Although vacation time is slowly approaching, I am still around for a dozen of days. Then I will take a break of a few weeks, during which my online activities are expected to decrease. Due to health issues that continue after I got COVID six weeks ago, I urgently need to rest and to get some D vitamins (if you see what I mean).
This planning therefore leaves us some time for a few physics blogs. For the post of the day, I decided to start with a question. How do you think new phenomena are searched for at CERN’s Large Hadron Collider? Please try to guess the answer, and consider to share your guess in the comment section of this post (before actually reading the post).
For those reading me week after week, I very often refer to searches for new phenomena at CERN’s Large Hadron Collider (the LHC). However, I have never taken the time to properly explain how those searches are made in practice. In many of my older blogs, I only mentioned that we start from a bunch of collision events recorded by the LHC detectors, and that we end with a comparison of predictions with data that allows us to draw conclusive statements.
This comparison assesses not only how data and predictions of the Standard Model of particle physics agree with each other, but also how much space is left for any new phenomenon. Equivalently, this estimates how theories extending the Standard Model are constrained by data, and how viable they are (still relatively to current data).
However, I have never given many practical details. This is the gap that this blog tries to fill. As usual, a short summary is available in its last section below, so that readers pushed for time can get the point in 3 minutes and 23 seconds (precisely ;) ).

[Credits: Original image by Daniel Dominguez (CERN) ]
1 petabyte of data per second!
The Large Hadron Collider has been designed to produce about 600,000,000 collisions per second in the ATLAS and CMS detectors. This means that 600,000,000 times every second, a proton of the first LHC beam hits a proton of the second LHC beam in any of the detectors operating around the machine.
600,000,000… This big number is a big problem. It means that we have that amount of collisions to record every second, which would correspond to an amount of data greater by several orders of magnitude than what any data acquisition system could handle.
This indeed corresponds to a rate of 1 petabyte per second, or the equivalent of 200,000 DVDs per second. I won’t translate in terms of floppy disks, although I am sure that some my followers definitely know what they are.
The good news, however, is that we don’t actually need to record it all. This allows us instead to solely focus on collisions that are interesting for physics purposes, which yields a recording rate of only about 200 megabytes of data per second. This smaller number is in contrast manageable by electronics.
This reduction from 1 petabyte per second to 200 megabytes per second is achieved by means of an extremely fast and automatic procedure, called a triggering system. More information are given below. In addition, a lot of details are available here for the CMS detector, and there for the ATLAS detector.

[Credits: Manfred Jeitler (CERN) ]
It is all about triggers
In practice, what this triggering procedure does is to scan a given event for deposits of large amount of energy, or for particle tracks with a significant amount of momentum. All collision events giving rise to very energetic objects are considered as potentially interesting, and they are thus candidate events to be recorded.
Other events, in which protons are collided and in which only final-state particles with a small amount of energy are produced, are common and very boring. There is thus no reason to keep them on tape. Consequently, the event rate is reduced to about 100,000 events per second, which is however still too much for any existing data acquisition system.
Thanks to a powerful computing system, the pre-selected events (100,000 of them per second) can be fully reconstructed, and thus further investigated.
There are numerous outcomes for high-energy collisions. Each of them is associated with a variety of final-state products that interact differently with high-energy physics detectors, and that leave tracks and energy deposits inside them. The reconstruction process that I mentioned in the previous paragraph allows us to go from these energy deposits and tracks to actual objects like electrons, muons, etc. Please do not hesitate to check out this blog for a list and more information.
In less than 0.1 second (we must be fast, 100,000 events per second being a huge rate), we can (automatically) look whether our 100,000 interesting events are truly interesting events. Do they feature particles typical of interesting processes, within the Standard Model (so that we could study whether it really works so well) or beyond the Standard Model (to have some potential to observe some new phenomenon)? Do these events feature anything unusual?
At the end of the day (in fact, at the end of few milliseconds), 100 events out of the 100,000 pre-selected events are tagged as “definitely interesting” and recorded.
In addition, we must keep in mind that everything that has been described above occurs every single second. With this drastic reduction (100 events per second out of 600,000,000 evens per second), each of the LHC experiments records about 15,000 terabytes of data per year.
Now we can play with this data to sharpen our understanding of the universe.

[Credits: Florian Hirzinger (CC BY-SA 3.0) ]
From terabytes of data to signal and background
The story of the day is far from being over. We need to provide to our 15,000 terabytes of data a small massage, so that we could extract information to be compared with predictions. Those predictions are both those inherent to the Standard Model of particle physics (we need to test it), but also those related to theories beyond it (to assess their viability and constraints).
This is where all the skills of a physicist (at least someone working on an LHC experiment) are needed. How to do that best?
A small number of the gazillions of recorded collisions must be selected for having their properties analysed. To know precisely what to select, we first need to know what we are looking for (that’s common sense, I know).
For instance, let’s assume that we are interested in the production of two top quarks (the heaviest known elementary particle) at the LHC, in a case where each of the top quarks decays into one muon, one b jet and one neutrino. I recall that a jet is a reconstructed object that indicates that the production of a highly-energetic strongly-interacting particle occured (see here for more information on how the strong interaction may change what we see in a detector). Moreover, a b jet originates from a b quark.
To write it in a short way, our signature consists in two muons, two b jets and some missing energy (neutrinos being so weakly-interacting that they escape any LHC detector invisibly). Therefore, out of the 15,000 terabytes of recorded collisions, our physics case tells us to focus only on collisions containing two muons, two b jets and some missing transverse energy.
[Credits: CERN]
As a result of this procedure, we select a good part of our top-pair signal, but not all of it. At this stage already, some events indeed escape us.
This occurs when they feature final-state objects that don’t carry enough energy, so that the reconstruction process does not yield the final state under consideration, or when some of the objects that we require are emitted in corners of the detector where the detection efficiency is small. In both cases, the effectively reconstructed event shows a final state different from that considered, so that the even is rejected.
The same as above holds for any other process of the Standard Model that would lead to the same final state. We therefore end with a bunch of selected events. A fraction of them correspond to our signal, and the rest to the background of the Standard Model.
The signal could be something that exists. In this case, we focus on the study of a process of the Standard Model, and we try to verify whether its properties match expectations. On the other hand, our events could be hypothetical ones. In this case, we study physics beyond the Standard Model, and we aim to verify whether there is an anomaly in data compared with the expectation from the Standard Model.
What about a needle in a needlestack?
In general, our signal is at this stage overwhelmed by the background. For signals of new phenomena, we could see this like looking for a needle in a haystack. However, the situation is in principle worse, so that we actually look for a specific needle in a needlestack.
There is thus a need to add criteria on the set of selected events. For instance, if we have two muons as final state objects, we could impose them to have more energy than a given threshold. Similarly, we could impose them to be almost back to back (or not too separated angularly).
The idea is to enforce selection tests that most signal events pass, and few background events pass. There are not 256 ways to know which selections to impose: we need to study the signal of interest and its properties. Moreover, this has to be done in a correlated way with the background to make sure that our tests actually kills the background more than the signal.
As an example, let’s focus on the figure below, that is useful on the context of searches for dark matter at the LHC.
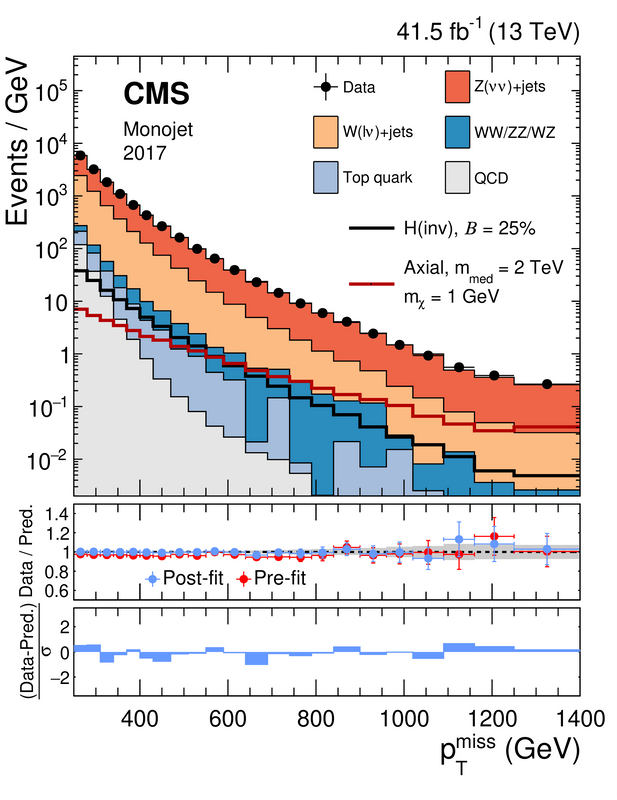
[Credits: JHEP 11 (2021) 153 (CC BY-4.0)]
Here, the CMS collaboration has selected events, out of all data that has been collected during the second operation run of the LHC. These events feature a lot of missing energy and a highly-energetic jet. This signal is a typical signal for dark matter.
Dark matter being expected to be weakly interacting with the particles of the Standard Model, once produced it escapes any LHC detector invisibly. Thanks to energy and momentum conservation, we can however detect what is invisible.
The reason is that we know the energy and momentum budget of the initial state. Conservation laws then tell us what we should get in the final state. Sometimes, we observe that energy and momentum are missing in the final state, which we indirectly attribute to weakly interacting particles like neutrinos or dark matter that leave us in a stealthy manner.
This is precisely what is reported in the upper panel of the figure above: the missing transverse energy spectrum originating from all events selected in the analysis considered. This tells us about the occurrence of events (the Y axis) featuring a small amount of missing transverse energy (on the left of the figure) and a large amount of missing energy (on the right of the figure).
Through the different colours, we stack the contributions of the different processes of the Standard Model. This consists of our background. Then we superimpose to the figure data (the black dots with their error bars).
We can see a very nice agreement between data and the Standard Model. Therefore, such a distribution can be used to constrain dark matter. The dark signal must be weak enough to be consistent with the absence of anomalies on the figure.

[Credits: The ATLAS Collaboration (CERN)]
How to build our favourite LHC analysis?
In this blog, I wanted to describe how we come up with physics analyses at CERN’s Large Hadron Collider. The machine is expected to deliver hundreds of millions of collisions per second. With 1 megabyte of data per collision (more or less), this makes it impossible for any data acquisition system.
For that reason, each detector comes with a dedicated system of triggers. Very quickly, this allows it to decide whether any given collision is interesting, or could be thrown to the bin. The goal is to reduce the rate to a hundred of collision events per second, which can be stored for further analyses.
This decision of storing or not an event is taken on the final-state products of each collision. It is based on questions such as whether there is any very energetic deposit in the detector, or whether there is any track of something carrying a large amount of momentum. We need energetic objects!
In a second step, a physics analysis, that usually takes a year or more to be realised, is put in place. The analysis focuses on a specific signal, which could be a Standard Model one (we want to study the properties of this or that particle) or a new phenomenon (do we have room for non standard effects for this or that process?).
The analysis is based on a selection of all events recorded, made from requirements constraining the particle content of the event and its properties. At the end of the day, the goal is to select, out of the terabytes of data stored, as many signal events as possible (here the signal could be a real one or a hypothetical one), and as little background events as possible.
After the selection, we verify how data and predictions match each other, and conclude. Is our signal in agreement with the Standard Model? Do we have an anomaly that could be representative of a new theory? And so on…
I stop here for today. I hope you enjoyed this blog and that you can now answer to the question raised in its title. Feel free to use and abuse of the comment section of this blog. Engagement of any form is always appreciated.






{kind=link}