Even the giants are having difficult getting the data needed.
It does not require a great investigator to come across headlines such as this:


People often say that data is the new oil. If this is the case, then we best wake up. When the likes of OpenAi, Anthropic, and others are on the prowl, this puts smaller entities at an extreme disadvantage. It also hand a tremendous amount of power to these firms, ones that have not exactly shown themselves to be trustworthy in the past.
When it comes to Web 3.0, perhaps the greatest utility that it provides, at least for the moment, is the democratization of data.
Democratized Data: The Equalizer
The reality is that without data, there is nothing. It is where the digital world is heading.
We are dealing with something much larger than simply seeing data harvest to sell to advertisers. Instead, we are watching the foundation of how the entire digital world will operate.
Once again, do we want this in the hands of Big Tech only.
To me, this is one of the most crucial moments we are facing. The entire premise of Web 3.0 is based upon this.
Here is the problem:
When a major technology company gets a hold of this data, it trains a model that is utilized by millions of people. There is a natural feedback loop where the results of the engagement generate more data. Guess who owns this data?
Another way to look at it is the model is generating synthetic data for the company. It is closed, not available to the public. This further shifts the playing field in favor of these entities.
Naturally, any data that is open these companies can feed in. The difference is that so can anyone. It is not only relegated to the major firms.
Of course, when you have a large enough legal team, there are other avenues.

Source
They are not above taking the data (if they can) and dealing with the consequences later. The first headline depicting OpenAI training its model on 1 million hours of YouTube videos is telling. It is against Google's terms of service but OpenAI doesn't care.
The challenge is if a smaller entity tried this, and was caught, Google's legal team would bury them.
It is why we need to generate as much open data as possible.
Web 3.0 AI Solutions
Fortunately, there are some solutions that are popping up. We see a few models that are worthy of testing. The key is to alter the feedback loop.
Before getting to the Web 3.0 solutions, we can start by undertaking a simple strategy. Each time we prompt something on a closed model, simply take the result and post it in an open database. There are a number of options out there, most of them tied to blockchain.
We can also use some of the AI models that are being appearing.
The two that I utilize are Venice.ai and Qtum.ai. Qtum has both a chatbot and an image generator (the chatbot is linked).
As an aside, when I did a comparison between Venice and Claude3 (the free version), Venice did hold up. These were simply prompts, so it might not perform when asking about coding or hard mathematical problems. Nevertheless, for simple prompts, it is decent.
Venice utilizes open source models. It has things such as Llama3.1 and Flux built in.
This model also is privacy focused, placing the results locally. There is no need to log in or create an account to utilize it.
Here is a comparison from the Venice.ai website.
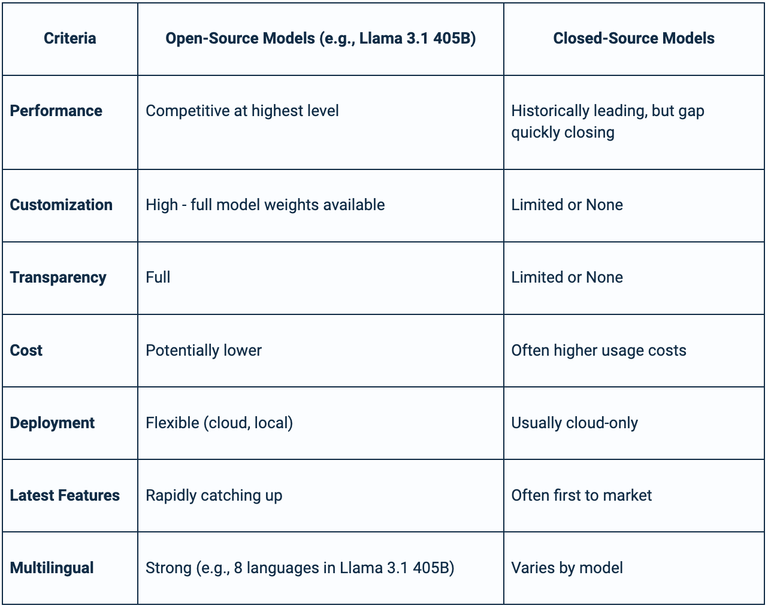
Qtum is a blockchain based solution. They are taking a different approach in that they are looking to implement a NFT system which can be created as something is generated by the individual. This means that using the model (for text or image) will, at some point, provide ownership.
Of course, all this data generated can be opened up simply by posting it to a permissionless database. Blockchain is very valuable in this regard since most are designed in this fashion.
Open Source Is Not Enough
It is great that Meta opened up Llama. However, that is still not enough. Zuckerberg is positioning his company to dominate the open source space. His goal is to control the ecosystem, with Meta at the center.
Even if we look at the data, using Llama3.1 still provides the feedback loop to Zuck. He gets all responses generated off Meta.ai. Anyone can get a hold of the software, along with the weights, but the data is off limits.
Certainly, the fact that other entities are feeding that into their models does help. This is why something like Venice, in spite of the limitations on prompts, is an option.
Ultimately, we have to ensure the feedback loop of data is in place. This means more being posted to permissionless databases. In my mind, this is essential to the essence of Web 3.0.
We are not going to have the next generation Internet if we are dependent upon closed systems that are housed on company controlled servers.
If we dig in, much of what we are discussing is still based upon the client-server architecture. That is the epitome of Web 2.0.
Data democratization is going to help meet the growing demand for data. People have complained for years how Big Tech "steals" it. If that is the case, why do people keep feeding it? Naturally, the ability to completely get away from these companies is hindered. That said, we see people volunteering to support them wherever they can.
AI models are just another example. How many are running to ChatGPT, Gemini, or Grok? As the technology expands, habits will likely take over and these companies will have people locked in.
This has to change. Firms are paying big money for data, creating a new system that is, by default, going to be closed. The solution is for everyone to realize how important the democratization of data truly is.
Posted Using InLeo Alpha
 )
)