
Introduction
I've been experimenting with a Machine Learning (ML) model to predict the rewards of a given post.
I thought that, maybe, using the total post HBD reward I retrieved on HiveSQL was not perfect. I came to think that the real driving force was the HP and thus, I should use the Hive reward on the post, and not the HBD reward. I was thinking that the variation of the HBD/Hive would impact the real "power" a post received.
I wanted to explore this path as the decisive feature of my ML model is what I called the "mean article payout". It is the average payout a poster got on his posts during the previous month.
As you can see on this graph, it accounts for more than 60% of the prediction:
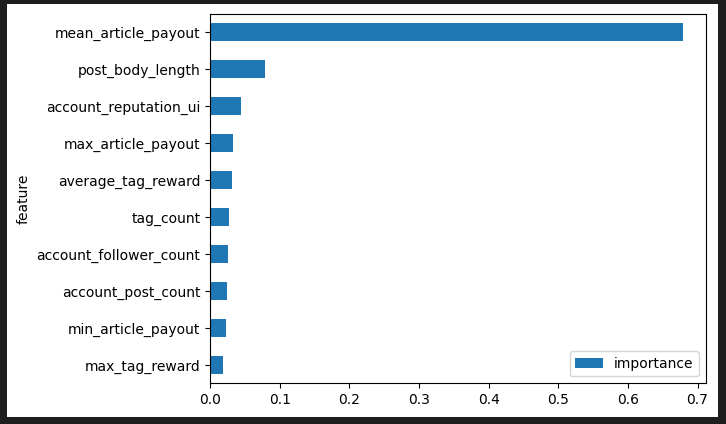
The length of the post is the second most important factor, followed by the account's reputation.
The latter had to be expected, as your reputation increases when you get upvotes. A high reputation denotes a lot of votes in the past. The "mean article payout" and the "account reputation" are thus dependent correlated variables, which is not a very good thing in ML Models.
Data Prep
After setting up my table with HDB/Hive values, I modified my Talend job (an ETL tool) to compute the Hive value for each post.
The Talend job is a crucial part of the data preparation in my model :
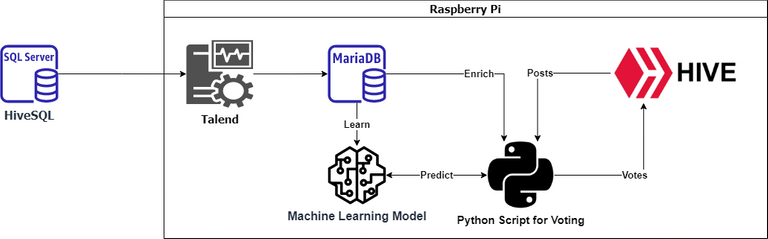
That's my pipeline architecture to illustrate the role of the Talend job.
There was a last question to answer : which HDB/Hive conversion rate should I choose? The one from the day of writing, or the one from the day of reward ?.
Having no insight into this question, I just ran some tests.
Tests
I decided to test both and here are the results :
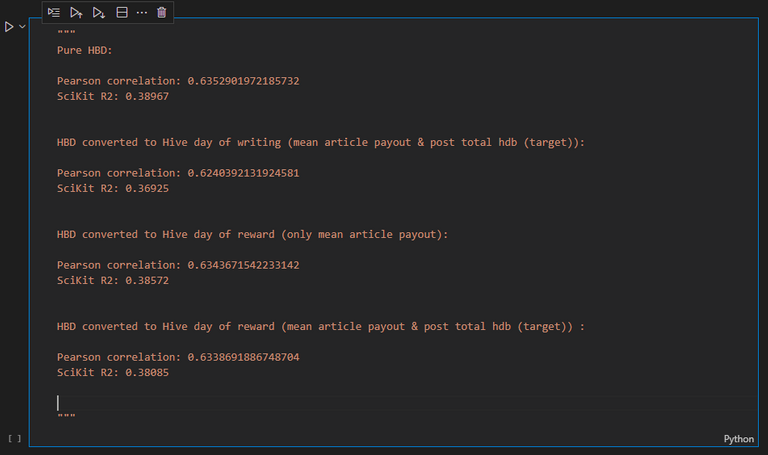
Long story short:
my idea was bad !!
I compared four situations :
- The original data source: pure HBD on the target (the post final reward) and on average last month post's final reward.
- HBD converted to Hive using the day of writing rate for both values
- HBD converted to Hive using the day of reward rate for both values
- HBD converted to Hive at :
- day of reward for the average last month post final reward.
- day of writing for the post final reward.
There was no ML training involved. I just tested the correlation between the two variables with the exact same set of data.
The results are clear: the original way is the best. There is no correlation improvement when converting to Hive, all my tests perform worse than my original data source.
Thoughts
I considered that, if my most important variable is less correlated, I'll have worse results on my model. That may not be exactly true. There could be other informations that the model could use that would explain it and that the ML model could take into account to achieve better predictions.
Still, I don't think it would justify the hassle of changing my whole pipeline.
Future
I may have an idea to use my HBD/Hive ticker in the future, but I have some searches to do first, and I'll make a post to cover it if I'm convinced.
Concerning the ML Model: it's working as expected. It's not very efficient but it works.
The main exploration path to increase the quality of the predictions is to find one or two more relevant variables. A good way to achieve this would be to isolate some authors whose post performs very differently from one to another.
A "manual curation" of those posts could maybe lead me to some interesting insights.
From my recent posts, I realized that :
- The posting community has a strong impact. At the moment, it's lost amongst all the tags in my model.
- It seems that without the Leofinance tag, a post won't appear on the leofinance interface (at least I don't see them in the "My Posts" tab). This has a big impact on the number of viewers.
- Some tags have a specific voter, with lots of trailing voters.
- Maybe the number (or presence) of links and pictures influence what a voter would consider a "good" or "bad" post.
- Many pictures could also artificially increase the post body size and should be removed.
Even if I don't really need to improve the prediction, those leads could be interesting to follow, just to build up my personal knowledge and understanding of ML models, and the Hive ecosystem as a whole!
Notes :
The introduction image was created with Bing Image Creator and the logos added with The Gimp.
