Today I'd like to do a bit of a deep-dive on this concept:
Immutable data makes edits trivial.
At first glance it sounds like a ridiculous oxymoronic statement.
How can edits be trivial when the data literally can't be changed?
And yet, peakd.com has an edit button.
LEOfinance.io has an edit button.
Hive.blog has an edit button.
Ecency has an edit button.
Liketu has an edit button.
How does that work?
Quite simply, every frontend to hive is controlled by a single centralized entity. A frontend can serve whatever content it wants to you. Many of them look quite similar because they draw data from the underlying blockchain in a similar way, but that's not a rule. A frontend can show you whatever it wants. You could click a button on any frontend thinking you were sending $10 to a friend when in reality the transaction drained your entire account. There's a certain level of trust involved when dealing with a frontend. The only way to avoid that counter-party risk is to run your own node and pull data directly from the chain yourself. Obviously not a viable option for more than 99% of the population.
Certainly, there are protections is place.
For example if you are signing transactions with Hive Keychain, a frontend that tries to trick you and steal your money could be easily sniffed out by simply looking at the operation data before clicking the confirm button. If you use Hive Keychain and actually check the operations before confirming them, then Hive Keychain itself becomes the point of vulnerability. Many people, including myself, trust this third-party app with our posting and active key. It would be nice if we had some kind of air-gapped cold-storage option, but what we have now is pretty good considering we never have to give anyone access to our owner key. Combined with account recovery, this gives us a lot of security.

Game Over
Another thing about Hive frontends (and crypto frontends in general) is the reputation aspect. A lot of time goes into coding these projects and building up a certain kind of brand name. If they stole from even one person that puts all the work that they've done in jeopardy. The vast majority of the time it would never be worth it to go blackhat in situations like this, which is why it basically never happens. But still, perhaps that gives users a false sense of security, and they should be reminded of the possibilities and how this tech actually works.
So how do edits work on an immutable blockchain?
Simple... we just overwrite the old data with new data, just like we would do if the data wasn't immutable in the first place. However, there's an important distinction here. Overwriting old data on an efficient database deletes that old data and frees up memory to be used elsewhere. Inefficient blockchain solutions keep all the data saved, no matter how many times the same comment was edited.
To give an example of what I'm talking about here, imagine trying to build a WEB2 app like Twitter. Where's the most basic place to start? On a fundamental level, a product like Twitter is basically just a database on the backend. You store accounts and emails and password hashes and whatever else.
The main functionality is Tweeting, Retweeting, and Liking content.
So imagine you have a table full of all this data.
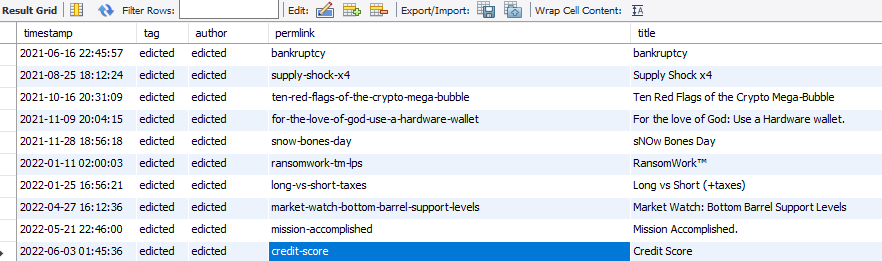
Something like this on the backend... but obviously this particular example is just me storing Hive data in my own database. Still, something like this wouldn't have to be modified much to store what is needed to make Twitter a functional platform. For example, it would still need a timestamp column. We'd likely add something like a tweet_id that would be a unique integer that represents each particular Tweet in an index that is sorted by the time in which the Tweet was made. The more people Tweet, the more the tweet_id code goes up. Just basic database stuff: see SQL primary key incrementation.
Considering that Twitter publishes 500 MILLION Tweets every day (hot damn that's a lot of data) even if it's all short-form text... That's still 13 gigabytes of data a day... all text. Apparently the average Tweet is only 28 characters long, which is what? Six words? lol. Ironically I bet 'lol' Tweets bring down the average, eh?
Scaling up to that level is actually quite impressive, and the examples I give are not how they actually do it, because how they actually handle that much volume is a little more tricky than just dumping all the data into a single database table and calling it good.
But for the sake of simplicity lets say there's a single table that does store all the information. It's got columns like 'username', 'tweet_id', 'body', 'reply_to', 'retweet', etc. In order to create threads, something like a 'reply_to' column would be needed so that we know if the current tweet we are looking at is a top level "What's Happening" Tweet (@null) or a response to a top level tweet (or a response to a response). reply_to would be an integer that points to the tweet_id of the Tweet it is replying to. We call this a foreign key in the database biz, because it references the primary key of another column (in this case tweet_id).
Are you still there? Are you following me?
It's fine if not, just keep reading it's all good.

In fact, now is a good time to step back and remember that our witness node @hextech published its first block on Hive block number 43,180,010. Wow! What a wild ride it's been. The current headblock is... 69,143,712... so wow, we've been operational for quite some time now (26M blocks, 28800 blocks per day, 901 days). We keep talking about booting up a badass full node but I'll let you know when it actually happens :D. Hive has been good to us, even as a non-consensus witness we easily turn a slight profit with Hive above 20 cents... which I don't spend any money from because I'm like the money guy and my witness partners are... shall we say... not. To be fair @rishi556 is still completing school and @sn0n is a Viking so they have unique expenses that I am not burdened with.
Back to the topic at hand.
So many people ask why Twitter wouldn't have an edit option. If you've been following along so far you may already be able to guess why. This is a curation issue. On something like Facebook you do not "retweet" other people's 'work'. On Facebook if you edit something, meh, no big deal. On a technical level, we go into the database and run the following SQL code:
UPDATE comments
SET body = 'This is my new edited comment,'
WHERE tweet_id = 5839572342;
This command then goes to the correct comment with id 5839572342 and changes the data from whatever it was to 'This is my new edited comment,' or whatever text we put into the field. If this was done on Twitter, everyone who retweeted that comment would now be retweeting the new data rather than the old data that they originally curated (because the retweet points to the same tweet_id and the old data was lost).
Again, not a problem on Facebook, because curation on Facebook works differently than Twitter. These are subtle details that casual users will never understand. They just complain about not being able to edit a Tweet without realizing what would happen if they had that ability. The solution creates another problem (just like a complex economy).
And we might try to make the claim that this is ridiculous and Twitter should just fix the way they do retweets. Just store a copy of the original Tweet so if it gets changed everyone who retweeted the before-version keeps the original curation intact. This is easier said than done during implementation.
For example, does that mean that every time anyone retweets anything a new copy of the same data needs to be stored over and over again in the database? Not only is this not a viable solution because Twitter processes 500M Tweets a day and they aren't that profitable of a business, but also bots/hackers would exploit that mechanic, retweet everything, and crash Twitter within minutes. Never underestimate the trolls and the Sybil attack.
So every edit to every Tweet would require a new entry in the database, and every retweet would have to point to the correct one based on the timestamps they were issued. This is a more viable solution than the previous example, but the level of complexity it adds is sure to create unintended bugs. It becomes a game of Whack-A-Mole where devs begin to realize that the code they just wrote isn't compatible with a bunch of other code they wrote somewhere else. So then they rewrite that code and then something else breaks, and again and again, like untangling a jumbled mess of string.

Good news boss: we got it working!
Okay now add an edit button.
Should be really easy.
Fuck...
The way blockchain and Hive works is COMPLETELY different than this.
Even though it is highly inefficient, we store all the data in immutable blocks that never change no matter what. A retweet would point to the block number and operation of the thing the user retweeted. If that tweet got changed after the fact, all of the old retweets would still point to the old data, while the new data would be reflected on the original poster's account. None of the data is ever lost, and therefore it becomes easier to manage without having to worry about how to organize it all.
It's also significant to point out the incentives in play. The only incentive Twitter has to run their nodes is that they are farming data and selling ad-space. Hive nodes have completely different incentives. We literally get paid to run them by the network itself. WEB3 is unique from the ground up. Data is inefficient and permanent, but data also costs resources to post to the chain. On Bitcoin, sometimes that means a $50 fee just to move money around during the bull market. On Hive, it costs resource credits (which are slowly going up in value over time).
Conclusion
The inefficiency of blockchain comes with huge benefits that are often overlooked and dismissed by mainstream society. The biggest advantage is that we get to create and intrinsically control our own currency, but also on the database level we see that the ability to point back to a specific block and operation on that block can be extremely useful on a technical level. As we begin to scale up, this will become more and more obvious to all who are paying attention.
Elon Musk may have bought Twitter, and Jack may be creating Bluesky, but there is nothing new being created. The incentives are exactly the same. WEB2.5 is not innovation, but rather the bastardization and hybridization of crypto into the legacy system. To be fair this is likely all part of the process. Growing pains are a necessary byproduct of exponential growth. When in uncharted waters such as this, learning the hard way is often the unavoidable outcome for those who are still entrenched within the old way of doing things. Luckily failure is an intrinsic piece of success; trial and error. All we can do is keep grinding. We will see what sticks and gets washed away by the volatile tide we find ourselves in.
Posted Using LeoFinance Beta