
Last year when I first started using Streamlit, I had to share my initial experience here on Hive. If you would like to read the post and see how fast and easy it is to get started with Streamlit, visit Streamlit - The Faster Way To Build And Share Data Apps. Since then I have been using Streamlit a lot, both for Hive projects and projects outside of Hive.
When I say I have been using Streamlit a lot, I mean the end result, and not the time spent on coding. The best part of Streamlit is it helps turning ideas into usable apps in no time. Usually, it doesn't take me to develop something for automating or reporting more than 2 days. However, my projects are usually small, and focused on specific and repetitive tasks.
What does Streamlit do?
It is a web framework for python based project. It converts python code into a web app that can be shared with anybody. This makes it a really useful for prototyping python projects. It was designed for data scientists, data analysts, and and everybody who work with data. It shines in presenting data analysis and visualization in a simple, yet power way. The idea behind it is that for python coders to focus on the goal of their project and spend smallest amount of time in creating a web app to share with teams, clients, and others who may be interested in the data presented.
The Streamlit team does deliver on this promise. It doesn't take much time in writing code for a Steamlit App. It become even faster once the initial configurations are set up properly. After the initial setup, any optimization and improving the code is only done with focus only on the purpose of the project.
I used Heroku to deploy my projects. But Streamlit has its own sharing platform as well, and they can host apps just like Heroku does. When I deployed my first app, and shared about it here on Hive and Twitter. Streamlit team noticed it as well and included among featured apps of the week.
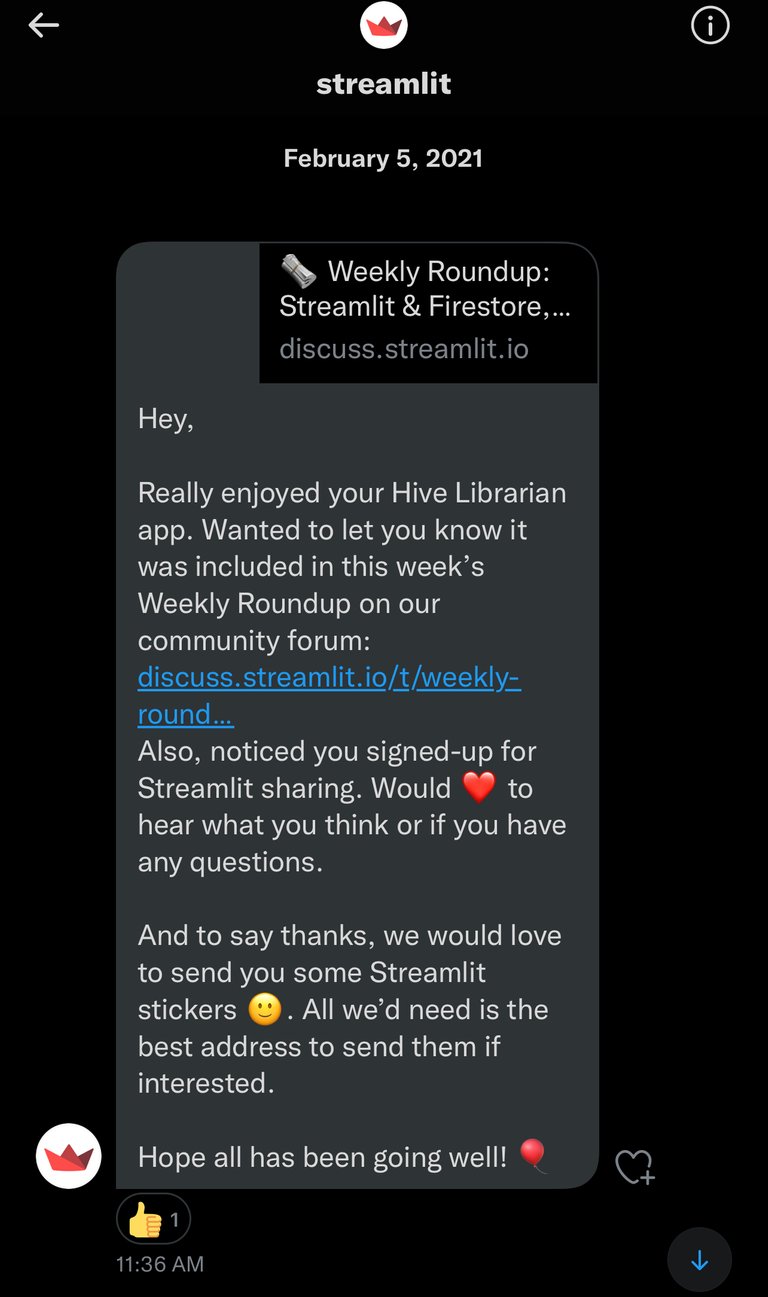
While original idea for Streamlit was to provide tools for data analysts to streamline their work, the creative use cases by the Streamlit community members demonstrated that Streamlit can be used for many different purposes. It can be used for general purpose apps, finance and crypto based projects, educational and entertainment purpose apps, etc. I initially used for my Hive Librarian, and Hive Search apps. Then I ended up creating personal use apps that extract data from pdf files, automate repetitive tasks, etc.
Deploying Streamlit Apps
First, to use Streamlit in python projects, we will need to pip install streamlit. The team has been continuously adding new features and making the framework even more efficient and powerful. To stay updated with Streamlit's new features we will need to update the dependency on our machine's too. However, sometimes these update may cause the old project behave differently and not as expected. It is advised to test after updates, to make sure everything is working as intended. I normally don't update, if everything is working ok. Why fix something that works? On the other hand it may be more useful to use the most updated versions for the new projects.
When developing a Streamlit based project, two of the common ways to deploy them fast and for free can be via heroku or Streamlit share. I used Heroku when I started. It has been working ok. I tried both free and paid versions. For a small or personal projects Heroku's free hosting may just be enough.
When developing an app, we can run streamlit run appname.py in terminal and it will run the app locally and open in a default browser. The cool thing about is as we make changes in the python code we can see the changes in the web app right away, while it is running. The easy way to deploy the app to Heroku I found is first storing everything in a GitHub project. This can also help with sharing the code, if the project is open source.
There are few files that we need to make sure exist in our GitHub project.
- Procfile
- requirements.text
- setup.sh
The Procfile will have one line as following:
web: sh setup.sh && streamlit run myapp.py
Replace the .py filename with a filename of your App.
Inside the requirement.txt we need to place all the modules/dependencies we used in our python script with their version numbers. Like this:
streamlit==0.74.1
pymssql==2.1.5
Pillow==8.1.0
We can get that information with typing the following in the command prompt or terminal
pip freeze
Last file setup.sh will contain the following.
mkdir -p ~/.streamlit/
echo "\
[server]\n\
port = $PORT\n\
enableCORS = false\n\
headless = true\n\
\n\
" > ~/.streamlit/config.toml
And of course we need to make sure that we have our main appname.py file, which will contain all the python code.
After everything is ready in GitHub, we go to our Heroku page and create our new app by clicking New and then Create new app. After giving a name to this new app, under Deploy tab and Devployment method we need to choose Github. It will ask for a repository name, and connects to it. Once, everything connected we click Deploy Branch at the bottom of the page. If everything goes well, at the end it will show a link to the App.
Every time we make changes or updates to the app, we will need to update GitHub files and repeat Deploy Branch process in Heroku. Just like that updates will be applied to the app.
Another important thing to remember when deploying a Streamlit app on Heroku is, not to leak confidential information like login credentials to database, api keys, etc. On a local machine we can achieve this by hiding such information in environment variables and get them in python code with os.environ. Using the same method, we can add this confidential information in Heroku Settings for the app. Under Settings, there is an option to enter Config Vars. We can store confidential information there.
What to build with Streamlit?
It works great for data visualization, especially if this needs to be shared with multiple people. However, it is not limited for data based apps. I was able to create two Hive based apps:
- Hive Librarian - https://hivelibrarian.herokuapp.com
- Hive Librarian Search - https://hive-search.herokuapp.com
Some of you may have used them already, as I have written about them in the past. Both of the use HiveSQL to get the Hive blockchain data. Hive Librarian is more of a collection of tasks. Here is the list of tasks it can do:
- Conversation: Returns conversations in the Hive comments between two accounts.
- Hive Rich List: Returns a list of ranked accounts based on various assets like HP, Hive, HBD, HBD in Savings, etc.
- HP Delegation: Returns information of an account delegation history.
- Hive Rewards: Returns various Hive rewards an account has received. The reasons for this addition was, some were looking for ways to get a list of rewards transactions to use in other tax tools.
Hive Librarian Search is a tool created for curating purposes. It helps with searching Hive posts based on curator's parameters. There are actually too many parameters to configure. Most won't need them all. Among the common ones are the reputation of the account, pending post rewards, when posts were created, topic or category of the posts, include/exclude tags or words, etc.
I also use Streamlit for crypto and stocks related projects. Another project I use Streamlit for is extracting data from pdf files. It is a great tool to prototyping testing various ideas and have a running web app in no time. However, don't expect to create the best website and web app with this. There are better tools available that are more suitable for web development. Streamlit is for projects that don't need a lot of time and efforts in web development. If Web design and the latest web trends are of highest priority, then perhaps other frameworks would be better option.
P.S. As I was finishing this post I realized that the apps I mentioned above are currently not working due not being able to login to HiveSQL. HiveSQL is probably going through some maintenance. Please try them later when HiveSQL is back online.
Posted Using LeoFinance Beta

