We are getting closer to Hard Fork 26. Of late, we are receiving some insight into what is being done. While this is not the stuff that gets the user base excited, there are some key things occurring which are vital for the future of Hive.
TLDLR: Hive's technical lead is getting larger
I often joke that Hive is the blockchain Vitalik is trying to build. Ethereum is getting a lot of headlines with the idea of "Merge". This is a major software update with one intention: scalability. We all know Ethereum is constrained. For this reason, they are switching from PoW to PoS.
This will likely have the intended outcome. However, they are doing version 1.0 while Hive is optimizing based upon much higher levels.
Before getting into some of the more overwhelming technical articles, let us highlight one feature that is crucial and can framed in terms of real world use cases.
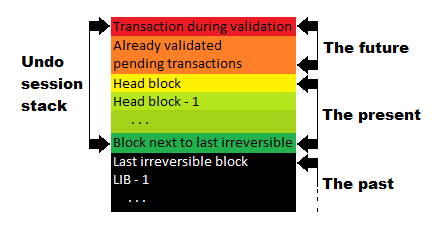
One Block Irreversibility
This is known as OBI. It is something that Blocktrades brought up a number of months ago and is now in the code that will go live with the next HF.
This from a post that we will explore in a bit.
lib - last irreversible block is so close to current block because OBI is already active.
So why is this important? We will go to the original post for the answer.
For example, if you operate a store that accepts bitcoin payments, you might not want to let your customer leave the store with their items until their bitcoin transaction has fully confirmed. For bitcoin, a block is generally considered fully confirmed when 6 further blocks have been built on top of the block (each subsequent block can be viewed as “vote of confidence” in the original block). With an average block production time of 10 minutes, this means you could be waiting about an hour (6 * 10 minutes) to be sure of your payment.
It is likely all of us can understand this. However, to go one step further, consider the idea of buying something online. Do you want to wait an hour (or more) to be able to downloads something after making a purchase? The answer is obviously not.
The is another reality on top of this: people are going to be upset if they have to wait 45-48 seconds for the download to start. When it comes to Internet, patience stands at near zero. Most of us will click "X" is a webpage takes more than a couple seconds to load.
One Block Irreversibility makes this obsolete. Now, as evidenced by the first quote, the totality of this happens near the current block. That means, with a second after a block is produced, it becomes irreversible. In our example, the download could start then.
We often discuss the idea of HBD becoming a legitimate player in the stablecoin world. The reality is that if we are going to make HBD the centerpiece for a payment system, OBI is vital. The commercial limitations of not having it are obvious.
Enormous Changes
Most of us are unaware of what goes on with base layer development. To the majority of us, even when explained to us in articles, it goes over our heads. Few care about this stuff. Instead, the question is always the same: when?
Unbeknownst to most of us, this hard fork is enormous. Here is a quite from the latest update post:
This hardfork has also taken the most time of any of the Hive hardforks to complete, and the sheer amount of work done to the hived blockchain software can also be seen in the number of merge requests (these are made to add features or fix bugs to the hived code base). Over the lifetime of Hive, there have been 484 merge requests merged into the hive code repository so far, and more than half of them have been merged since the last hardfork.
So basically, we are looking at:
First 5 years: less than 242 merge requests
HF26: more than 242 merge requests
It seems we might be able to sum it up as more than 5 years of coding in one hard fork.
So what did all these merge requests pertain to? Without having the slightest clue about coding, it is safe to say some of it was the Resource Credit delegation feature that will be included. This is something, from the user perspective, that is vital going forward.
However, my sense is all this reverts back to scaling. Just like the core development team at Ethereum is trying to "make things go faster", so is the Hive team. It appears this is on track.
One thing I learned is we are dealing in a world where the timeframe is milliseconds. This is the metric used. It might not seem like much, what is 3ms or 5ms after all?
When it comes to millions of transactions per day, this can add up. So scoffing at the notion of efficiency improvement of a few ms is misguided. That is huge when coupled with a host of other upgrades.
It all comes back to optimizations. Hive is aiming to process data more efficiently than any other blockchain out there. Some of the solutions going into HF26 will aid in that.
What Does All This Mean?
Here is where we can get into a lot of technical stuff. For those inclined, here are three links explaining what is happening (here, here, and here).
As for the rest of us, we will use the pictures provided from these articles to tell the story.
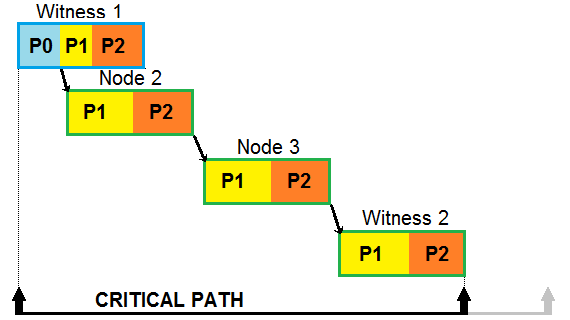
This is a node and what was called the three phases:
Read from the bottom up to see how data comes in and the timing of the different aspects.
From here, we can start with the baseline of how blocks are produced now. This is what was drawn.
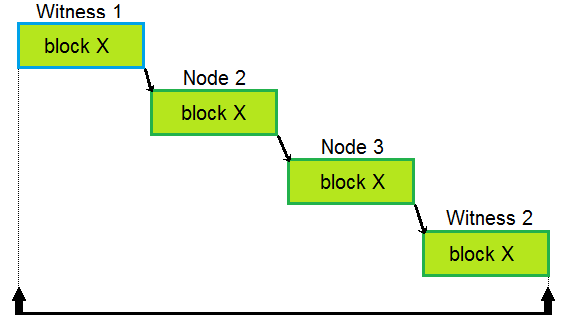
Basically, what we have is each node does its thing before handing it off to other nodes, which starts their process. Keep in mind, we are talking milliseconds. Also, notice the line at the bottom, this will show the contrast.
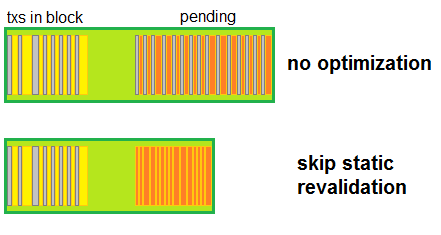
The optimization starts by skipping static revaluation.
Expired transactions are no longer processed like we didn't knew they expired. Since it is way cheaper to make a check outside the main code (and I mean waaay cheaper; in one test where I had over 100k pending transactions that all expired in the same time, original code could drop less than 5k of them per block, after changes all 100k+ were dropped easily within the same timeframe).
Again, using simple math, that does sound impressive. However, in keeping with the picture theme, this is what we see:
The next step is to calculate transaction invariants once.
Remember how in previous paragraph I said that all checks were still performed when new block is produced? Well, since new blocks are made solely out of pending transactions, and the node has done static validation on them already, it makes no sense to do it again.
So the elimination of doing the same thing multiple times. This makes a lot of sense.
Moreover, while witness has to verify signatures, the calculations leading to it, namely extraction of public keys from signatures, is also an invariant (actually it depends on chain id, which changed in HF24, but in this case it doesn't make a difference anymore). Incidentally it is also a costly process, so it pays to only perform it once.
Saves money too which we like. Efficiency, or a lack thereof, does some with a financial cost.
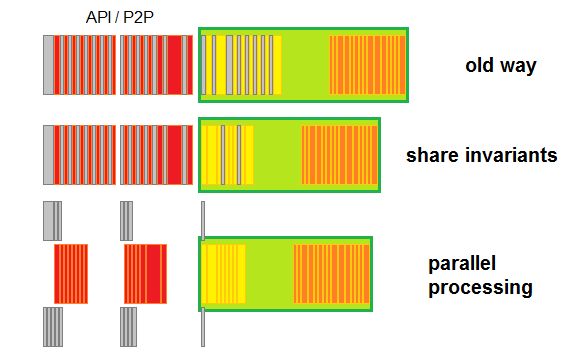
All of this leads to this outcome:
Again, look at the line at the bottom. It shows a geographical representation of the efficiency gained through this optimization process.
From the looks of things, this is very impressive. That said, we have to add in the proverbial "but wait, there is more".
Scroll back to the node picture above. With the past, present, future spelled out, we can see how this equates to Phases 0, 1, 2.
Instead of waiting the the final two phases to be done, the data for Phase 1 is shared as soon as completed. This starts the processing for the next node earlier.
The results are as such:
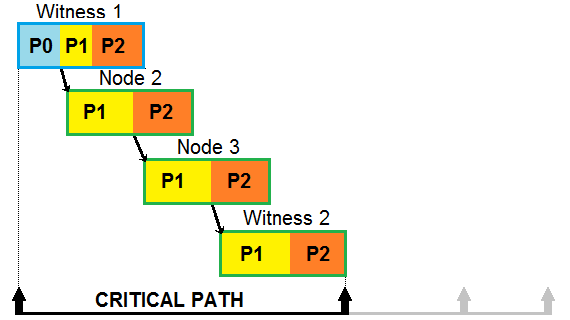
Even more improvements in terms of the optimization of the data processing.
So How Fast Are Things?
To answer this, we will refer to this article:
After all our recent transaction/block optimizations, we ran benchmarks with the new code exposed to transactions levels 20x higher than current traffic levels. These tests were performed both with 128K blocks (2x current size) where lots of transactions don’t get included due to limits on the block size, and 1MB blocks (16x current size) where all transactions typically did get included into the larger blocks, and in both cases the new nodes respond without even a hint of a hiccup.
In other words, we can throw a lot more transactions at the base layer infrastructure (post hard fork) and it will be able to handle it.
Thus, even though Hive is nowhere near capacity, the transaction capability is about to expand a great deal. It is always better to get the horsepower before it is needed.
What are your thoughts on these upgrades? Let us know in the comment section below.
Special thanks to @andablackwidow for the images. All images taken from articles linked
If you found this article informative, please give an upvote and rehive.

gif by @doze

logo by @st8z
Posted Using LeoFinance Beta





