We spend a lot of time discussing data. The reason for this is we are looking at the fundamental unit towards the establishment of artificial cognitive abilities.
For many, the idea of data is the end point. Most are aware that companies like xAI and Meta take the data placed on the social media platforms, feed them into neural networks, and out pops a model.
At this point, millions of people using prompts to generate images, get answers to questions, or search for information.
On its own, this is remarkable. Consider where things were a few years ago and how long it would take to achieve this using tools such as image editing tools and search engines.
It is important to understand how far we have come in such as short period of time.
That said, this is nothing more than a beginning. In this article, we will work out way up the scale a bit.
One Of The Goals Of AI: Insights
AI comes with a great deal of hype. Many believe we are looking at another example of a new technology being overhyped. On this, I disagree. If anything, the impact of what we are going to see will eclipse the comprehension of most. Simply look at the progress over the last couple years and extrapolate that forward over 30 months or so. Of course, we have to use an exponential rate since that is what we are seeing according to most AI metrics.
Many feel the hype of AI comes from the fact there is not a great deal of utility. Since we do not see a lot of applications, it is easy to dismess.
There are a couple challenges with this.
The first is the fact that a lot of this is blended into the platforms we utilize. AI is considered a general purpose technology. How often do we notice the impact of electricity? Do we focus upon that each time we turn on the computer at work? Or do we simply take the productivity that results from having devices powered by electricity for granted?
AI will end up the same way. We are seeing some of the larger platforms incorporating this. It will be to the point where people will not even notice what is taking place. Quite frankly, a lot will operate on the backend with the rest simply becoming normal.
Which brings us to the second issue.
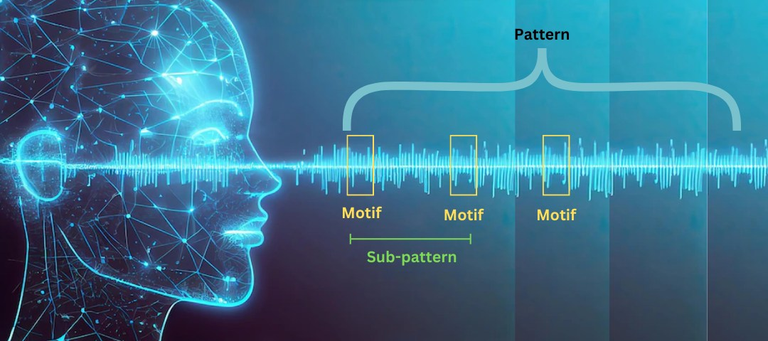
AI is a natural extension of what computers do exceptionally well. They have perfect memory along with the ability to process as massive speeds. This combination makes them ideal for pattern recognition.
In other words, as we move up the AI scale, we can expect the capability to garner insights from what is being produced. Hence, the data that is provided all feeds into the system of insightful recognition.
An example of this could be lung scans. Medical practioners are feeding in millions of scans into systems. Over time, they start to pick up patterns, most of which go unnoticed by humans. Here is where the raw ability for compute along with perfect memory enters.
How many scans can a doctor look at? Over decades, maybe tens of thousands. An AI system can go through millions of lung scans, while seeking out the finest details.
Web 3.0 Insights
Where are these insignts coming from? Who is in control of them? These are always the essential questions to me.
Of course, with something like lung scans are canceer screenings, privacy is expected. This is not something that people want posted online. However, there is a lot of information that does not fall under this category.
To provide systems that are adept at recognizing patterns, the data first must be available. We know that Big Tech is doing whatever they can to acquire this. The next phase of the evolution is going to be real world data.
As we covered on a number of occasions, Big Tech is already positioning itself to dominate here, at least in the medium term. It is why Web 3.0 advocates have to generate as much permissionless data as possible.
Here is a quick example of how far things still have to go.
Many know that Wall Street firms have proprietary trading models which allows computers to autonomously trade markets. This is based upon decades of data regarding stocks, bonds, and interest rates. These companies spent tens of millions of dollars building the databases along with the software.
Much of that data is available through oracles. For this, there is a cost. Where is the free version of market data? It is out there but hard to come by.
Naturally, it is difficult to built open trading programs at the same level since the data is not widely available. Perhaps recent data could be garnered, along with the process of "going foward". That said, imagine the benefits of having decades of market data instantly available.
Even if that was scraped, where is it resident? Having that information on the servers of OpenAi doesn't really help.
Since data is the foundation, all other advancements up the development scale are impacted. A rung higher is the insights that come from the pattern recognition of massive amounts of data. To achieve this result, said data must be available.
Big Tech is acquiring it, what about everyone else?
Here is where the masses can have an impact.
Posted Using INLEO
