
When I talk about navigation, I mean reaching different elements of DOM using JavaScript statements. Let me explain more. According to the World Web Consortium (W3C), everything in HTML is considered a node, that is:
- Every HTML document is a document node
- All HTML elements are an element node
- The text inside HTML elements is a text node
- Each Attribute is an Attribute node (of course, this item is obsolete)
- All comments are comment nodes
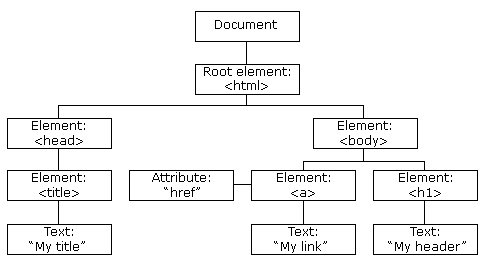
Everything you see in the HTML tree is a node. Nodes can be deleted, edited or recreated.
These nodes, as you can see in the picture, have a kind of hierarchical relationship with each other, each of which is a subset of the other. To describe this hierarchical relationship, we use words that it is better to explain here:
- root is the highest node in a document
- Each node, apart from the root, has a parent. The parent node is the node in which the rest of the nodes are located.
- Each node can have a number of children (in English they say children). Children of a node means nodes or elements that are inside it.
- Sibling nodes are actually nodes that have a parent.
Look at the code below:
<html>
<head>
<title>DOM Tutorial</title>
</head>
<body>
<h1>DOM Lesson one</h1>
<p>Hello world!</p>
</body>
</html>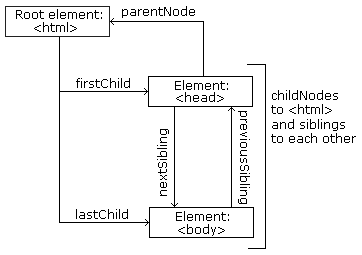
Looking at the code and its image, we can see that:
-
<html>is the root (it is higher than other nodes) -
<html>has no parent -
<html>itself is the parent of<head>and<body> -
<head>is the first child of the<html>element -
<body>is the last child of the<html>element
also:
-
<head>has one child:<title> -
<title>has a child which is a text node: "DOM Tutorial" -
<body>has two children:<h1>and<p> -
<h1>has one child: "DOM Lesson one" -
<p>has one child: "Hello world!" -
<h1>and<p>are siblings
To navigate and move between these nodes, the following statements are used:
-
parentNode -
childNodes[nodenumber] -
firstChild -
lastChild -
nextSibling -
previousSibling
The difference between elemental and textual nodes
Look at the code below:
<title id="demo">DOM Tutorial</title>
In the example above, we have an element node (<title>) that does not contain any text! Rather, it contains a text node, and that text node's value is equal to "DOM Tutorial"! Usually, novice programmers do not understand that element node is different from text node.
Now, if we want to access the value of this text node, we must use the innerHTML attribute:
let myTitle = document.getElementById("demo").innerHTML;
If you remember, we said that innerHTML means the content inside an HTML tag or element. So using innerHTML to access the inner content is like using nodeValue for the first child in this example:
let myTitle = document.getElementById("demo").firstChild.nodeValue;
In this statement, we first say get the first child (which is a text node), then give us the nodeValue or the value of the node.
Accessing the first child can also be done in this way:
let myTitle = document.getElementById("demo").childNodes[0].nodeValue;You can see that in this method we have used the index of arrays.
Below I have given you three different examples that all three do the same thing; They take the <h1> text and then copy it into the <p>. I have done this so that you can get acquainted with different methods of working with nodes.
<!DOCTYPE html>
<html>
<body>
<h1 id="id01">My First Page</h1>
<p id="id02"></p>
<script>
document.getElementById("id02").innerHTML = document.getElementById("id01").innerHTML;
</script>
</body>
</html>
In this example, we have used the same simple method as innerHTML.
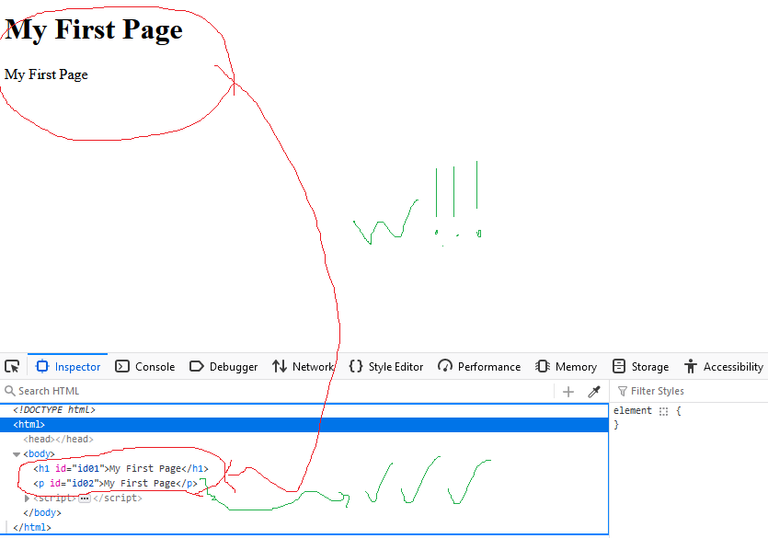
<!DOCTYPE html>
<html>
<body>
<h1 id="id01">My First Page</h1>
<p id="id02"></p>
<script>
document.getElementById("id02").innerHTML = document.getElementById("id01").firstChild.nodeValue;
</script>
</body>
</html>In this example, I have used navigation. That is, first I have found the child node and then I have taken its content.
<!DOCTYPE html>
<html>
<body>
<h1 id="id01">My First Page</h1>
<p id="id02"></p>
<script>
document.getElementById("id02").innerHTML = document.getElementById("id01").childNodes[0].nodeValue;
</script>
</body>
</html>In this method, I have also worked in the form of array indexes.
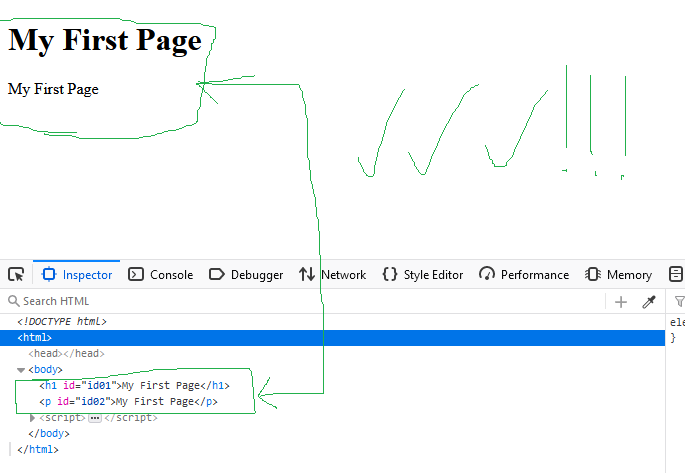
There is no difference in these methods and it all depends on your work situation and taste. Since the innerHTML method is simpler than other methods, I use the same method in this post.
Root access
There are two main ways to gain root access:
-
Using the
document.bodystatement that gives us the body of the document -
Using the
document.documentElementstatement that gives us the entire document
<!DOCTYPE html>
<html>
<body>
<p>Hello World!</p>
<div>
<p>The DOM is very useful!</p>
<p>This example demonstrates the <b>document.body</b> property.</p>
</div>
<script>
alert(document.body.innerHTML);
</script>
</body>
</html>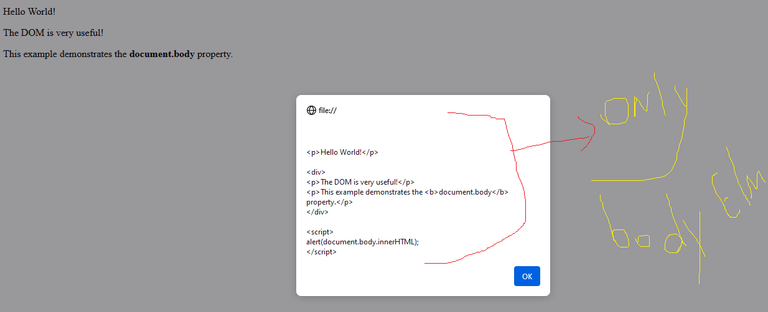
In this example, due to the use of the document.body statement, only the body of the document is given to us. It means what is placed in <body> and we don't have <head> codes.
<!DOCTYPE html>
<html>
<body>
<p>Hello World!</p>
<div>
<p>The DOM is very useful!</p>
<p>This example demonstrates the <b>document.documentElement</b> property.</p>
</div>
<script>
alert(document.documentElement.innerHTML);
</script>
</body>
</html>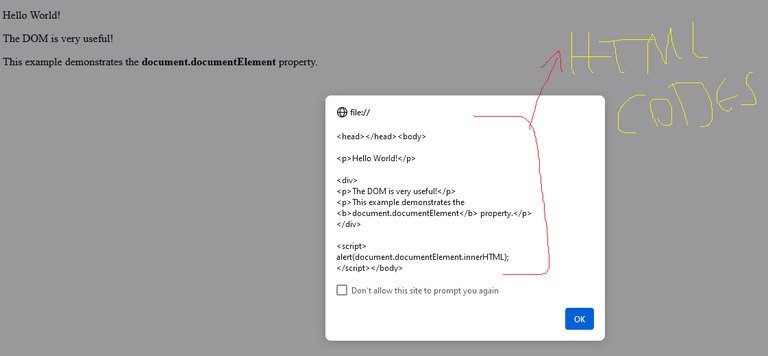
In this example, I have used the statement document.documentElement and you can see that it has given us all the codes of the page
nodeName, nodeValue and nodeType Statements
The nodeName statement specifies the name of a node and:
-
nodeNameis of read-only type; That is, it can only read values and cannot change anything -
The
nodeNamecorresponding to an elemental node is actually the tag name -
The
nodeNamethat is related to an Attribute type node is actually the attribute name -
The
nodeNamecorresponding to a text node is always #text -
The
nodeNamecorresponding to a document node is always #document
<!DOCTYPE html>
<html>
<body>
<h1 id="id01">My First Page</h1>
<p id="id02"></p>
<script>
document.getElementById("id02").innerHTML = document.getElementById("id01").nodeName;
</script>
</body>
</html>
Note: nodeName always provides tag names in uppercase.
The nodeValue statement returns the value of a node and:
-
nodeValuecorresponds to an elementary node,null -
nodeValuecorresponds to a text node, the text itself -
nodeValuecorresponding to a node of attribute type is the value of that attribute
The nodeType statement also returns the type of a node and is read-only. Example:
<!DOCTYPE html>
<html>
<body>
<h1 id="id01">My First Page</h1>
<p id="id02"></p>
<script>
document.getElementById("id02").innerHTML = document.getElementById("id01").nodeType;
</script>
</body>
</html>
The returned value in the example above is 1! To understand what 1 means, take a look at the table below:
| Node | Type | Example |
|---|---|---|
| ELEMENT_NODE | 1 | <h1 class="heading">Albro</h1> |
| ATTRIBUTE_NODE | 2 | class = "heading" (deprecated) |
| TEXT_NODE | 3 | @ocdb |
| COMMENT_NODE | 8 | <!-- This is a comment --> |
| DOCUMENT_NODE | 9 |
The HTML document itself (the parent of <html>)
|
| DOCUMENT_TYPE_NODE | 10 | <!Doctype html> |
Note: The number 2, which is related to attributes, is deprecate in HTML.

