After the last adventure in statistics another exploration. Today we will be looking at DAGs.

DAGs are a systematic way of finding the link between correlation and causation. Suppose we have a phenomenon X and a phenomenon Y. We want to see how X influences Y. So if the relation is such that X directly influences Y to as denoted by X → Y, then everything is simple but normally there are also other variables in play. In the last post we saw an example of this. These other variables can mess around with the link between correlation and causation.
To aid us in finding causation in the correlation we can use DAGs or Directed Acyclic Graphs. Graph here means vertices connected by lines, as these are Directed graphs these lines have direction, so they are arrows, and finally as the graph is acyclic when we follow these arrows we never go round in a circle. This was maybe all a bit technical so let's look at an example.
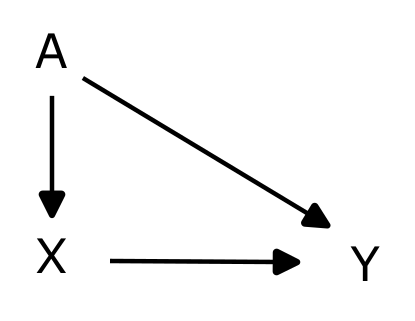
We want to see how X influences Y (in a statistics book X is typically referred to as predictor variable and Y outcome variable). There is a direct link between X and Y but there are also another path between X and Y as a result of A:
X ← A → Y
This other paths is problematic because it influences both X and Y so directly measuring the connection between X and Y we don't know how much they are influenced by A.
So how can we remove this influence? The trick here will be to see how the arrows move through the paths and conditioning in a proper way on a variable in that path. Conditioning means that in a sense I am going to fix it. For example if a variable is gender. Then conditioning on that variable means that I will look at male and female separately. Here in the example we can condition on A and this gives a the ability to obtain a causal relation between X and Y.
In real statistical problems there many issues which can add more difficulty to discovering causality. For example certain variables might not be observable in the sense that we know that are certain variable is present and we know how it relate to others but we cannot measure it or the data is so bad that is does not constitute a proper measurement. But still in these case you might be in luck in the sense that you can condition on another variable to close the path as in the example.
References: This post is based on Chapter 6 from McElreath's Statistical rethinking which is a must read. There is also a lovely series of lectures by him on the book
Cat tax




