For my English-speaking readership, this post is the adaptation in French of this older post discussing new phenomena that could occur at particle colliders, and how my own research work allowed us to re-use existing LHC results to probe new theories of particle physics not considered so far.
Cette semaine, je poursuis le sujet abordé dans le blog de la semaine dernière (ici), afin de discuter l’une de mes publications scientifiques récentes. On parlera ainsi d’analyses de physique en collisionneurs de particules, et de recherches d’aiguilles dans des bottes d’aiguilles (n’est-ce pas @emeraldtiger).

[Crédits: Imagine originale du CERN]
Cette recherche d’aiguilles dans des bottes d’aiguilles n’est pas une tâche insurmontable, comme en témoignent les dizaines de résultats expérimentaux publiés chaque semestre (voir par exemple ici et là pour les recherches de phénomènes dits ‘exotiques’ par les collaborations ATLAS et CMS du LHC).
Dans toutes les publications correspondant à ces analyses, la stratégie permettant d’identifier la bonne aiguille dans la botte est détaillée, et les prédictions sont comparées aux observations. De façon plus pratique, en effectuant des simulations pour tel ou tel signal, on peut conclure quant à sa viabilité au vu des données, et extraire des informations sur une découverte potentielle (en raison d’un excès ou déficit de données par rapport aux prédictions) ou sur l’absence de toute nouveauté.
Une grosse partie de mon travail de recherche est dédiée à la façon dont les physiciens (ou en fait n’importe qui) pourraient réutiliser les résultats expérimentaux publiés pour tester d’autres modèles. Il existe en effet de nombreuses théories qui méritent d’être testées, et mes collègues expérimentateurs sont trop peu nombreux pour tout vérifier par eux-mêmes. Ainsi, avoir des outils numériques permettant de faire de tels tests en dehors des collaborations expérimentales est super utile. Je travaille sur le développement de tels outils, et c’est le sujet du jour !
Comme d’habitude, pour celles et ceux pressés par le temps, une version courte du blog est proposée à la fin.
1 petabyte/seconde de données et une analyse de physique
(et nous et nous et nous)
(et nous et nous et nous)
Le Grand Collisionneur de Hadrons, le LHC, est une machine dans laquelle se produisent 600 millions de collisions par seconde. La quantité d’information obtenue est donc bien trop importante pour être stockée intégralement sur disque. Comme visible dans le titre de cette section, on parle d’1 petabyte/seconde de données. Heureusement, seule une faible partie de ces données est utile.
Chaque détecteur du LHC est équipé d’un système de déclenchement (ou ‘triggers’ en anglais), tel que visible sur la figure ci-dessous. Ce système permet de décider extrêmement rapidement si une collision donnée est intéressante, et s’il est utile de l’enregistrer. La décision est prise sur base de la quantité d’énergie déposée dans le détecteur (on étudie ce qu’il se passe à haute énergie) et la nature des particules qui y sont observées.

[Crédits: ATLAS @ CERN ]
Ce système de trigger permet de réduire le taux de données associé à nos collision à environ 200 MB/seconde. Et ça c’est électroniquement gérable ! À ce niveau, nous sommes cependant encore loin d’une analyse de physique. On se retrouve en fait à devoir étudier ce qu’il se passe dans environ 15000 TB de données par an. Ça nous donne grosso modo la taille de notre botte d’aiguilles.
Que faire ensuite ?
La première étape revient à définir le signal qui nous intéresse. Recherche-t-on de la crotte de licorne rose, de la physique du Modèle Standard de la physique des particules, ou un phénomène nouveau comme par exemple une signature de production de matière noire ?
Supposons, pour fixer les idées, que l’on s’intéresse à un signal de physique menant à la production de deux muons et de deux électrons.
On va alors prendre toutes les données enregistrées, et sélectionner les événements (c’est-à-dire les collisions enregistrées individuelles) qui contiennent deux muons et deux électrons. On peut ensuite rajouter des critères spécifiant l’orientation relative de nos quatre particules. Par exemple, on peut imposer que les muons ont été produits dos-à-dos dans le détecteur, tandis que les électrons se déplacent plutôt parallèlement.
Après avoir imposé notre liste de critères de sélection, on se retrouve avec un certain nombre d’événements sélectionnés. Mais que faire avec cela ? Il nous faut à présent comparer le nombre d’événements observés à ce qui est prédit par la théorie, en prenant en compte à la fois le signal et le bruit de fond.
[Crédits: CERN]
Dans cette optique, nous allons nous baser sur des simulations numériques. Dans le cas d’un signal du Modèle Standard, on simulera le signal étudié, ainsi que le bruit de fond venant de tous les autres processus du Modèle Standard donnant un état final similaire à celui du signal. Dans le cas d’un signal de phénomène nouveau, c’est pareil à part que le bruit de fond consiste en les prédictions obtenues à partir de tous les processus du Modèle Standard donnant le même état final.
On peut donc comparer ce qui est observé dans les données à ce qui est prédit pour le signal et le bruit de fond, et voir dans quelle mesure le signal est observé ou exclu (attention, les deux alternatives nous permettent d’apprendre quelque chose). Cela s’effectue à l’aide de tests statistiques plus ou moins poussés.

[Crédits: CERN]
Analyses et sous-analyses
Seulement voilà. Une analyse au LHC est légèrement plus compliquée que ce qui est écrit ci-dessus. Chaque analyse inclut généralement un certain nombre de sous-analyses, appelées régions de signal (ou ‘signal region’ en anglais).
Si l’on reprend l’analyse d’un signal avec deux électrons et deux muons introduite dans l’exemple ci-dessus, on pourrait imaginer une première sous-analyse dans laquelle on étudierait un signal où les quatre particules ont pour origine la désintégration d’une nouvelle particule unique très massive, et une seconde sous-analyse où l’on suppose que deux nouvelles particules identiques ont été produites, et que l’une d’entre elles s’est désintégrée en électrons et l’autre en muons.
Au final, avoir de multiples sous-analyses revient à étudier en même temps de nombreuses variations d’un signal donné. Il existe ainsi des analyses ayant des dizaines, voire plus de cent régions de signal. Comme nous n’avons aucune idée de ce que les nouveaux phénomènes que l’on traque peuvent être, il est bon de considérer toutes les options imaginables.

[Crédits: CERN]
Avoir plusieurs sous-analyses offre aussi un autre avantage. Supposons que de nombreux excès soient observés dans diverses sous-analyses, mais que chaque excès individuel soit statistiquement compatible avec l’hypothèse du bruit de fond. Il pourrait se trouver que la combinaison de tous les excès observés pointe (de façon statistiquement significative) vers un phénomène nouveau.
Cette combinaison de sous-analyses ne peut cependant être faite n’importe comment. Il existe des corrélations entre les différentes sous-analyses (notamment en ce qui concerne les diverses incertitudes), et il faut les prendre en compte dans les tests statistiques (sous peine d’être trop agressif ou trop pessimiste dans nos conclusions). Cela nous amène à un problème important.
Bien que les résultats publiés par nos amis expérimentateurs et amies expérimentatrices incluent ces corrélations (l’information est connue et/ou calculée au niveau des expériences), cette information n’est généralement pas publique. Par conséquent, toute personne externe aux collaborations expérimentales est dans l’impossibilité d’effectuer cette combinaison, et ne peut donc tester de façon optimale son signal favori. On ne peut en effet que prendre en compte la meilleure des sous-analyses pour le test d’un signal donné, ce qui implique souvent des résultats trop conservateurs (ou trop agressifs dans des cas plus rares).
Le changement c’est l’an dernier !
Récemment, les collaborations expérimentales ont commencé à rendre l’information des corrélations entre sous-analyses d’une même analyse publique. Cela reste très rare, et il est crucial que nous, théoriciens, montrons que c’est super utile pour l’étude de nos modèles de physique afin de fournir aux collaborations la motivation pour que cette approche devienne systématique.
Dans la publication discutée dans le présent blog, nous avons introduit une mise à jour d’un logiciel que je co-développe depuis plusieurs années. Cette mise à jour permet à toute personne de non seulement réutiliser les résultats d’une analyse de physique du LHC, mais aussi de prendre en compte l’information (si elle est disponible) sur les corrélations lorsqu’on évalue la sensibilité du LHC à un signal donné.
On peut donc tester les signaux de physique de façon plus précise, en exploitant du mieux possible une analyse donnée (et toutes les sous-analyses qu’elle inclut).
Nous allons illustrer le gain d’une telle approche dans la figure ci-dessous. On considère un signal où la théorie contient plusieurs particules non standard qui se désintègrent les unes dans les autres. Toute la phénoménologie du modèle peut s’extraire à partir de deux paramètres, M2 et MQ3. Des petites valeurs de ces paramètres impliquent des nouvelles particules légères, et des grandes valeurs des particules lourdes.
Les signaux associés à ces nouvelles particules peuvent a priori être étudiés par plusieurs analyses existantes. Ici, on considère une analyse de la collaboration ATLAS (ATLAS-SUSY-2018-31) et une analyse de la collaboration CMS (CMS-SUS-19-006), qui contiennent toutes deux de nombreuses sous-analyses.
Nous allons évaluer la sensibilité du LHC au signal une première fois en considérant la meilleure de toutes les sous-analyses de chaque analyse, et une deuxième fois en combinant l’information. Autrement dit, nous allons évaluer quelles paires de valeurs (M2, MQ3) sont exclues en utilisant la sous-analyse la plus optimale de chaque analyse, et quelles paires de valeurs (M2, MQ3) sont exclues en combinant toutes les sous-analyses. Et ce bien sûr pour l’analyse ATLAS et l’analyse CMS indépendamment.
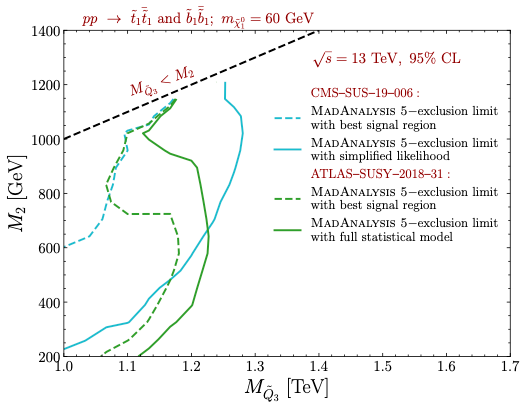
[Crédits: arXiv:2206.14870]
Dans la figure ci-dessus, nous voyons deux jeux de courbes : les courbes vertes correspondent à l’analyse ATLAS considérée, tandis que les courbes turquoises correspondent à l’analyse CMS. Toute paire de valeurs (M2, MQ3) se trouvant à gauche d’une ligne en pointillés est exclue lorsque l’on considère la sous-analyse la plus optimale (de l’analyse CMS en turquoise et de l’analyse ATLAS en vert). Pour les traits pleins, c’est pareil mais on effectue une combinaison des sous-analyses.
On peut observer que la zone à laquelle le LHC est sensible est bien plus grande une fois la combinaison mise en place. Cela démontre le gain en sensibilité à un modèle lorsque les choses sont faites du mieux possible ! On exploite en fait les résultats de façon optimale !

[Crédits: Florian Hirzinger (CC BY-SA 3.0) ]
Un test plus optimal des modèles de physique au LHC
Dans le blog du jour, j’ai discuté comment les recherches de signaux de nouvelle physique (ou nouveaux phénomènes) au LHC sont effectuées, et quels étaient certains des problèmes lorsque l’on essayait d’utiliser les résultats publics pour tester de nouveaux modèles.
Chaque analyse contient en général un certain nombre de sous-analyses. L’existence de ces sous-analyses permet de tester un nouveau phénomène sous toutes ses facettes, et des conclusions plus robustes peuvent être obtenues par la combinaison des observations associées à chaque sous-analyse. Cependant, la prise en compte des corrélations existant entre les différentes sous-analyses est cruciale pour effectuer un test de façon correcte, et ces dernières ne sont pas forcément disponibles publiquement.
En tous cas, c’était le cas jusqu’à ce qu’il y a peu. Récemment, les collaborations expérimentales du LHC ont commencé à publier ces corrélations. Avec mes collaborateurs, nous avons mis à jour l’un de mes logiciels afin de pouvoir prendre cela en compte lorsqu’un modèle de physique est testé. Ces tests peuvent alors se faire de façon optimale. C’est le sujet de cette publication, que j’ai discutée plus longuement dans ce blog. En gros, ça marche et ça cartonne (voir deux figures ci-dessus pour s’en convaincre) !
À présent, il est temps de s’arrêter d’écrire… N’hésitez pas à faire coucou en commentaires ! A bientôt et bonne fin de semaine à toutes et tous !


{kind=link}