
Have you ever wondered how programs and software work? If you've ever coded or are learning to code, you've surely wondered how code is executed. In this tutorial, we will examine the methods of running the code on the computer together. We will also get acquainted with the concept of compiler and interpreter in languages.
First of all, I want to thank @cadawg,@deathwing,@rishi556,@edicted and also to @resonator, @newageinv, @yaroschain, @canadian-coconut, @howo, @steemstem, @v4vapid and @minnowbooster who supported me with their upvotes and also to all those who express their opinions with their comments. I'm grateful to all of you.
Computer hardware is electronic components that use electrical current. Electricity can be off or on. In the computer, it is called 0 and 1.
In order for the computer to understand something, we have to talk to it in the language of zero and one or binary. In fact, everything that is executed or stored in the computer is in the form of 0 and 1.
As you know, one of the categories of programming languages is the division based on the level of language implementation. Machine code or machine language is strings 0 and 1. Then there are low-level and then high-level languages.
Programming with zeros and ones is very difficult and unnecessary for most of today's applications. Therefore, we use high-level code to instruct the computer. But these codes must eventually be converted into machine language. In the following, we will get acquainted with the methods of converting high-level code into machine language.
The process of executing code and programs
Every computer program consists of a number of instructions. These commands are executed in the computer processor and the final result is what we see.
If a program is written in a programming language other than zero and one, it must first be converted to 0 and 1 and then sent to the processor. The process of converting high-level codes to 0 and 1 code is called code translation.
There are two ways to translate programmed codes:
- Compile the code (using the compiler)
- Interpreting the code (using interpreter)
Every programming language executes its codes in one of these two ways. As a result, we can divide programming languages into two categories: compiler languages and interpreted languages.
In the following, I will talk in more detail about the working method and the advantages and disadvantages of each, but if I want to explain these two concepts very quickly and simply, it is as follows:
In compiler languages, written codes are translated at once. After translation, we will have a file containing the machine level codes for the current operating system and hardware. From now on, whenever we want to run the program, we just need to run the final (compiled) file.
When running code in interpreted languages, each line of the program is translated at the same time and sent to the processor for processing. While the program is waiting for its execution, the next line is translated. In this case, we need an interpreter for that language to run the program, but our codes will not depend on a specific system.
How the compiler works
In compiler languages, we first write the program code. These codes are called source code. Then we compile it and deliver a file. The final file is called object file. This file is the translation of our code into machine language. To run the program, just run the translated file.
When we run the compiler, our code will be checked by the compiler and the equivalent commands will be generated for the machine. The machine code is stored in another file (other than the original source code) and after that we have to run the translated file to run the program.
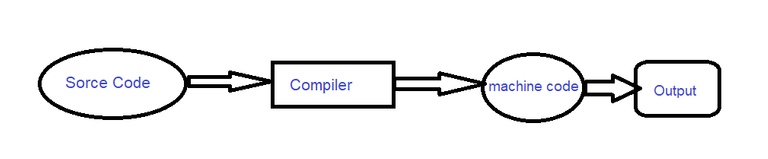
Each microprocessor has its own set of instructions. Also, the way to access different resources in different operating systems is different from each other. As a result, the compiler has to generate machine code according to the system it is running on.
By this definition, any code translated by the compiler will work on a variety of operating systems and hardware. If we want to run our code on another machine, we have to do the compile operation again.
Compile time error is one of the errors that occur in programming. Usually we get this error if the used libraries are not available.
C, C++, BASIC and SWIFT languages are among the compiler languages.
Features of code execution by the compiler
In compiled languages, our code is translated into machine language only once, and then it can be executed several times. As a result, we will have a faster execution of the program.
If we need to debug the code, because we have to do the compilation process once after each change, we usually have a more difficult debugging process than interpreters.
Surely you know that the compilation time depends on the amount of code and the dependencies we have in our code. Therefore, in a small (multi-line) project, the step of compiling the code with the help of IDEs may not feel much!
Assuming that our machine and operating system are similar, we only need to use the compiled file to run the program. Therefore, in this particular case, we will not need any software.
How to run the interpreter
Interpreted languages, sometimes called interpreters, compile the code at the same time as the program is running. In this way, the first line of the program is converted into machine code and sent to the processor, then the interpreter goes to the second line and does the same for it.
The meaning of being interpreted is the translation of high-level code into machine-level code (0 and 1). It is clear that in order to run the code in this way, we must have the interpreter of that language.
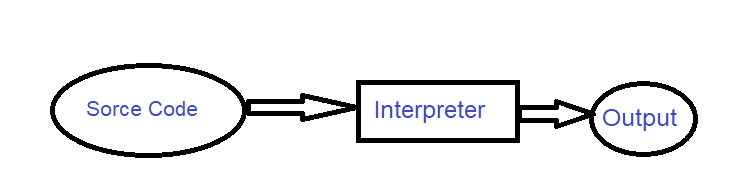
Unlike the compiler codes that gave us a file containing machine codes, interpreter codes are instantly converted into machine code and run; As a result, we do not have access to their machine code in the usual way.
PHP, Python, Perl, JavaScript and Ruby are among the popular interpreted languages.
Code execution features in the interpreter
If we want to run a program ten times, the interpretation process (code translation) must be done ten times! Interpreted languages are slower than compilers due to line-by-line translation at runtime. Because in addition to the execution time of the machine code, we also have to wait for the translation of each command.
Because the execution of interpreted codes are executed line by line, the process of debugging and correcting program errors is easier. With the help of IDEs, we can see the result of these codes line by line and notice its changes more easily.
Because the execution of these codes requires an interpreter, so wherever we want to run the program, we must first install the language interpreter. But their advantage over compilers is that we can run the written code on any system and machine.
Combined implementation of compiler and interpreter code
This type of code execution belongs to the category of compilers. But some believe that this type of implementation is a combination of compiler and interpreter and we need to consider a new category for them.
If we want to examine the two advantages and disadvantages of compiler and interpreter, the result is that the compiler increases the speed of code execution, but it depends on the system. On the other hand, interpreters have a lower speed, but they are independent from the system. (Two differences between compiler and interpreter)
Some programming languages try to be somewhere between the two. In such a way that they first convert our code (the main code of the program) into an intermediate code (IL). Then run this intermediate code on all systems through its interpreter.
The language that became known with this idea and was very successful in achieving this goal is the Java programming language.
In this language, our codes (in .java format) are translated by the compiler for the Java virtual machine. With this, we have a .class file that can be executed by the Java virtual machine.
The Java Virtual Machine (JVM) is a program that is installed on all systems. In fact, this virtual machine runs the .class files as an interpreter on the main machine, which is our computer.
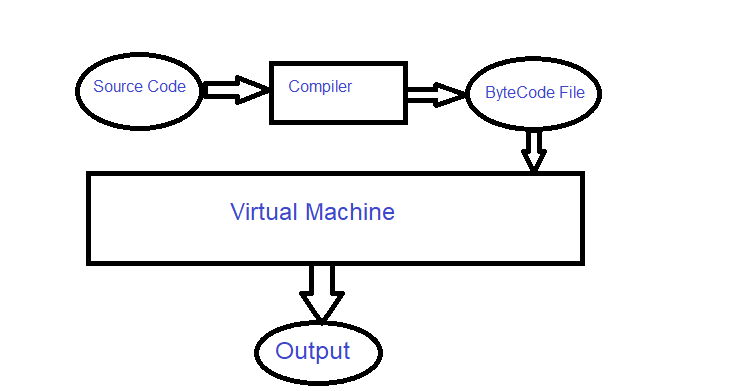
With this idea, the process of translating programmed codes is divided into two stages: compilation (offline translation) and interpretation (online translation). In such languages, it is enough to write and compile the program code once. Then, any machine that has the desired language virtual machine can run this program.
In fact, an intermediate layer or a platform for executing programmed codes is created between high-level codes and machine-level codes.
Files compiled in these languages are called byte code files. Also, this type of interpretation is sometimes called a bytecode interpreter.





