Usually, I'm mostly looking at AI projects that are developing useful tools for public use, like ChatGPT, Midjourney, etc. This time we are going to take a look at some of the cutting-edge research happening in the field of AI, including models that are pushing the boundaries of what's possible with vision-language processing, embodied language modeling, and even our brain activity. These projects showcase the potential of AI to not only solve practical problems but also to expand our understanding of the world and ourselves.
Prismer: A Vision-Language Model with Multi-Modal Experts
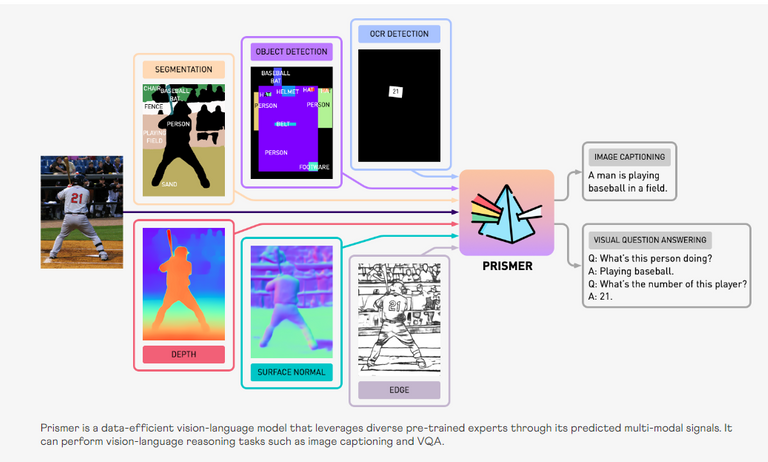
Prismer is really pushing the limit of what Vision-Language Models are able to do. We can see in the image above what this is all about. Prismer is able to analyze an image and then answer questions about it. The amazing part is the way Prismer can brake down the image and the amount of information it can generate from it.
It can recognize and segment out different layers on the image, it does object detection, and it can also do OCR detection (detects numbers and text). It can detect depth, surfaces, textures, materials, etc. Basically it can detect pretty much anything a human would by looking at the image. This can be confirmed by its automatic image captioning which said for this example "A man is playing baseball in a field". They are able to confirm it even further by asking it questions about the image.
Their example was:
- Q: What's this person doing?
- A: Playing baseball.
- Q: What's the number of this player?
- A: 21.
This tech is pretty much-taking image recognition to a whole new level. Not really a tool specifically helpful for humans but just imagine how much information will computers be able to extract from minimal input. This makes me wonder how much will this help with the development of autonomous robots.
Prismer is being developed by NVIDIA so I think we can expect a high-quality implementation of this technology.
PaLM-E: An Embodied Multimodal Language Model
Speaking of robots and image recognition, Google is doing something incredible too. Who would've thought, right?
Abstract:
Large language models have been demonstrated to perform complex tasks. However, enabling general inference in the real world, e.g. for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks, including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.
This little embodied AI fellow is supposedly able to do a variety of complex tasks. Basically, PaLM-e is able to understand and use information from the real world to plan out and complete these tasks. PaLM-E is a type of language model that can understand and use language. The interesting thing about PaLM-E is that it can also see things, hear things, and sense things around it using sensors. You can tell it for example, "Go get me a beer from a fridge", the robot will process the instruction and do that task.
Since PaLM-E is a multimodal language model (MLM but not a scam), it can do other things as well. Provide answers to questions, something like ChatGPT, and also analyze images in a way that previously mentioned Prismer can.

It recognizes relevant information in the image to answer the question.

It can recognize where the situation is heading.

or it can respond with emojis.
Of course, it can do so much more. If you are interested in how all this works in-depth I suggest you take a look at their paper here.
The potential of this tech is simply amazing. Right now this embodied AI is slow and kinda clumsy but with the rapid advancements, we've seen in the past 12 months or so it wouldn't be surprising to see this kind of AI-powered robot jumping around and doing all kinds of stuff.
As with any technology like this, it is important to consider the potential ethical implications and dangers of robots like these on the loose. I hope they won't be rushing it just for the sake of progress and that they will take all the precautions necessary to develop it safely.
Aside from taking our jobs, these helpers could help us with a variety of menial tasks and I'd imagine being of huge help to our elderly and people with disabilities.
Stable Diffusion with Brain Activity
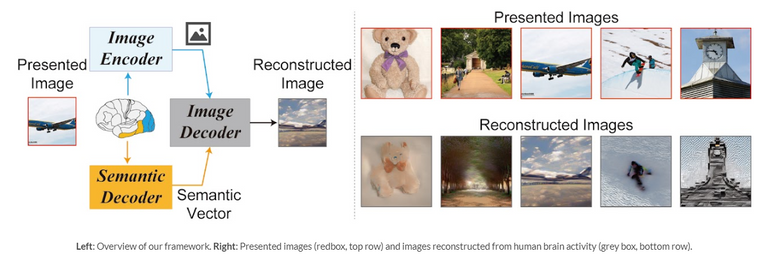
Now, this is a spooky one. Researchers have been able to go from showing a person an image while using functional magnetic resonance imaging (fMRI) to record their brain activity and then using the Stable Diffusion model to denoise and reconstruct the image from that information.
In other words, they developed mind reading!
Just look at those results above. This is how far we've come in actually reading someone's mind. It's amazing and terrifying all at once. But I guess this is becoming a standard with AI technologies, haha.

What you see here is the process itself. The starting noisy image is information recorded with fMRI that was fed to a specifically trained Diffusion model that is able to denoise those images and give us these results.
This tech is so wild! One of the cool things about it is that it gives us a fresh way to figure out how our brains make sense of the world. This can help us learn more about how we see and process visual information. Plus, this method can be used to interpret the connection between computer vision models and our visual system, which can give us further insight into how to improve AI's understanding of visual information.

I have to say it again, this tech is wild! Seeing all these projects led by big players like NVIDIA, Google, and OpenAI really makes you wonder. Where does this end? I mean, we are literally going to read people's minds sooner or later. So far we have some clumsy robots and low-detailed images but soon enough they will become top-level athletes who can see what we are thinking.
What do you guys think about how far away we are from these crazy scenarios?
As always thank you for reading.
Sources:
Prismer - https://shikun.io/projects/prismer
PaLM-e - https://palm-e.github.io/
Their paper - https://arxiv.org/abs/2303.03378
Stable Diffusion with Brain Activity - https://sites.google.com/view/stablediffusion-with-brain/home?authuser=0
Their paper - https://www.biorxiv.org/content/10.1101/2022.11.18.517004v2


 Create your own Hive account HERE
Create your own Hive account HERE



