I didn't know which community I should put this post in, thought about Hive Gaming but this post is a bit more technical, and then decided to go for SteemGeeks but the post turned out to be not so technical. Caught between the two, GeekZone fits perfectly, I suppose. It will be my first post in this community as well.

AI playing Chrome Dino, only did 2 Hours of Training
For the past few days, I have been working on a small AI project. This fits perfectly with my New Year's resolution to use my programming skills and relearn all the things I was passionate about just a few years ago.
I am a Computer Science graduate and when I was in college, I used to research all the new technologies and around those days I found out about Machine Learning and Artificial Intelligence. These were just the technologies of the 'future' back then and I had fun playing with some of the Machine Learning algorithms back in those days.
Now that everyone is using the term AI, even if they don't have the slightest clue what it does. Anyway, I digress. I was keen on learning some reinforcement learning models and what better way to learn them while having some fun too?
So, let's try to teach our AI to play a simple web-based game like Chrome's Dino. Just type this chrome://dino in your browser and it opens up. I bet you have seen it before.
How does AI learn?
But wait, how does the AI learn to play the game? Well, there is an interesting, we can use something called Reinforcement Learning. Think of it like training a dog. You give the AI some treat if it does the task correctly and punish it for doing it wrong. By playing games over and over they will eventually learn to do the task which gives them maximum rewards. That's what a reinforcement learning model is. You can go into Deep Neural Networks and weights and loss functions etc, but for now, this is enough.
Now, let's go a bit deeper on how it works.
- You feed observational data to your Network (Screenshot of the game, so it receives the data as pixels on the screen)
Action and Rewards
- You define inputs it can do for each step, for our simple game (it will be something like: no action (our agent does nothing), press down a key, press space.
- Assigns rewards... for my model, I gave a reward of +1 for every step it stays alive, a small positive reward (+0.1) for doing nothing, and a huge negative reward for losing the game (-10).
Then it is time to set some more parameters like how long you want your model to train, how frequently you want your model to update the model, what would be the learning rate etc.
Once this is done, you let it play games over and over and just wait and see it learn new techniques and strategies. At this stage, you carefully monitor the learning process and adjust some parameters if required.
It took me a long time to figure out a lot of things in the code. The worst part for me was to optime the code as much as I can so the learning is not too slow. You have a trade-off between model quality and training time.
At the start of the training, my goal was to see the AI reach a score of at least 500 in the game. I wasn't aiming for anything above that because this is a fast-paced game and you need to make quick decisions. With my computational limitation, it was a fair goal to aim at.
I made a little video showing how the AI learns to play this game. I saved my models at various positions so I can go back and play those and see how they perform concerning the total training time.
The results were certainly interesting.

Weakest model, spamming random inputs
The first model at 5000 steps or after 25 seconds of training was just as trash as you would expect. The AI just tries a bunch of random inputs to see what rewards they get. And for the set of inputs or experiences that gave it the best rewards, they would be used to tweak the model gradually and that's how it will learn.
With only about 25 minutes of training which took 30,000 individual steps (actions), the agent quickly learned to jump over the cactus. It wasn't consistent but you could see that it learned to jump just before it saw a cactus approaching. How cool is that? All we gave was a set of pixel information and the model had to figure out how to extend its life in the game so it could get the maximum rewards and only less than 25 minutes in, it learned to jump over some of the obstacles.
After 40+ minutes of Training
After a few more minutes at around 41 minutes, it becomes more consistent with the above approach. It could easily reach scores of more than 200 but this is the time when the game speeds up and the later models too a lot of time to adjust to this speed change. This was the first time when we saw the AI encounter a bird and didn't know what to do. It just slammed right into it.
This increased game speed and the addition of obstacles like birds made it recalculate its approach and for the next one hour or so, it didn't learn much. Much it was just exploring and finding all the possible solutions to encounter this new thing in their environment?'
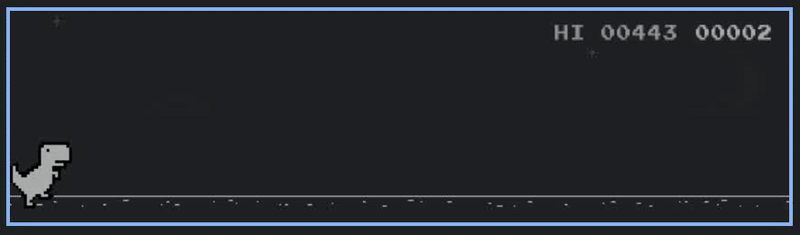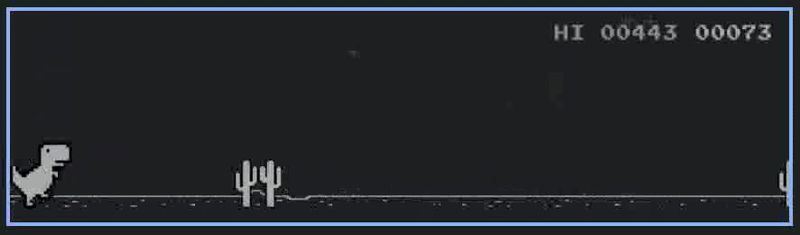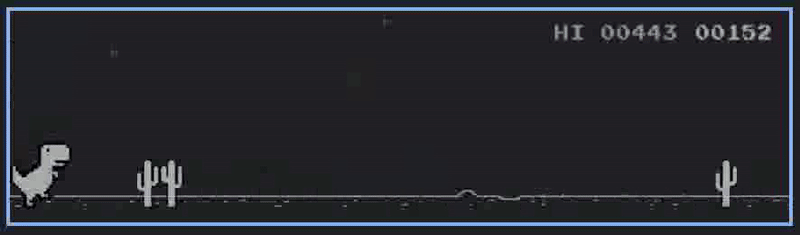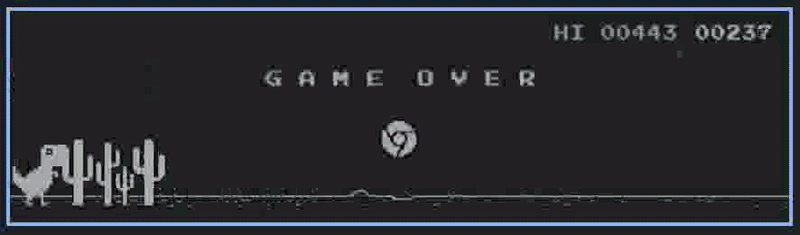
Decreasing in performance after some point, Case of Exploration-Exploitation Dilemma?
That's exactly what happened when we got the breakthrough at around 160,000 Step models (trained for more than 2 hours). This was the first time when it started to jump over some of the birds. It wasn't consistent enough and the learning became quite slow at this point. Maybe the significant increase in game speed was throwing it off and it was learning at a lot slower rate than before. This is natural for models like this as well.
This model broke through the 500 score mark and is already playing better than a kid. Just imagine if the model was not running at 20 fps and was learning at 60 fps and I had a lot of time to train it and test it. It could easily beat me if I train it long enough. I might not do it because it will be quite slow and time-consuming. But I achieved what I wanted to do with this project.
My best-performing model, learnt to deal with some birds too (a bit inconsistent)
Why and What else in Future?
Well, my main goal was to learn more about Reinforcement learning and having some hands-on approach. I can confidently say that seeing your model learn right in front of your eyes is one of the best feelings I got in my short coding career. Can't wait to try this approach with more complex games.
I have a really messy Jupyter Notebook filled with a lot of debugging code and other craps that will confuse the living heck out of everyone not just the AI chatbots. I took the help of some online AI models for debugging and some of them work better than others. The best free one was the DeepSeek latest model, it solved an issue that even Gemini couldn't but their servers are mostly busy so that sucks.
I will clean up the code and put some comments and upload it to my Github once I feel it is somewhat presentable xD. It will help me save my code for future reference. Just because I tend to forget things I already learnt.
