Those who watch the world of Large Language Models (LLM) were surprised at the release of Grok 2.0. This was something that was not expected especially since xAI entered the game a little over a year ago. Their first public version went online last fall, about a year after OpenAi released ChatGPT 3.0.
Naturally, with the introduction of that in November of 2022, everything changed.
Grok will have a lead until the next version of Claude, ChatGPT, or Llama is released. This is how it goes in the AI game.
However, as they say, you ain't seen nothing yet.
As impressive as the results are, we have not hit the knee of the curve yet. When that happens, people will be blown away.
Here is what it looks like.
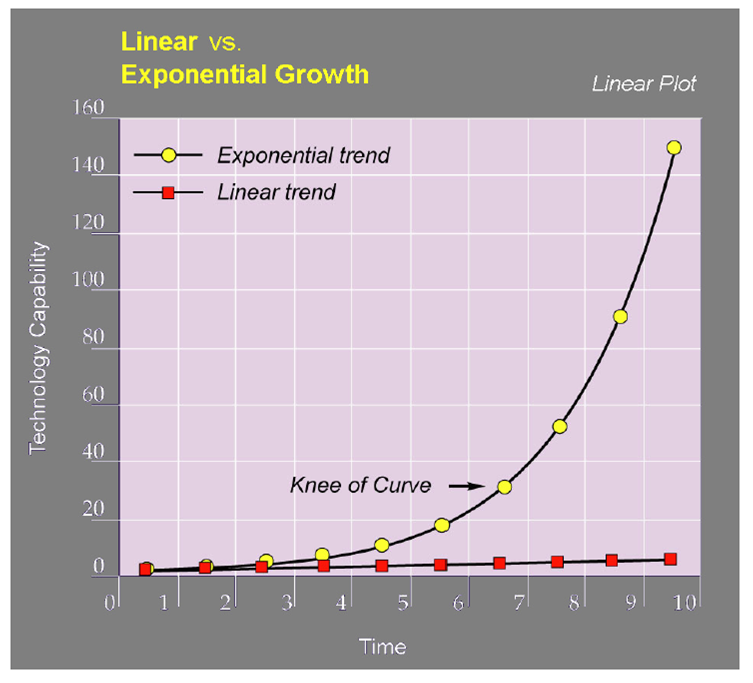
Source
Next Generation LLM Sends Us Exponential
The challenge with exponential curves is they can often seem to be rapidly advancing in the early stages. As stated, the progress made in about 20 months is impressive. That said, we cannot be fooled.
So why do I say the next generation will be the game changer?
Before answering that, it is important to state what we mean. When I mention next generation, I am referring to ChatGPT 5.0, Grok 3.0, Claude4 and Llama4. This is where everything could change.
Why do I make this claim?
It really comes down to compute. When we look at what is taking place, we can see how things are massively expanding.
A few weeks back, Meta was the rage with the release of Llama3.1. This was impressive against the benchmarks of the other models. Those who tested it out found it to be of the caliber of the top end.
Here is what the Meta blog has to say about it:
As our largest model yet, training Llama 3.1 405B on over 15 trillion tokens was a major challenge. To enable training runs at this scale and achieve the results we have in a reasonable amount of time, we significantly optimized our full training stack and pushed our model training to over 16 thousand H100 GPUs, making the 405B the first Llama model trained at this scale.
It is amazing how quickly things can become outdated.
Grok 3.0 is going to eclipse Llama 3.1 and by a wide margin. The reason for this is because xAI now has 100K H100 in its super cluster. The difference in compute means we are dealing with something that is going to be far advanced from today.
Of course, we can bet the house that Meta is not training Llama4 on the same 16K GPUs. It is likely going to require 5-10 times that amount. We do not know what Anthropic is doing with Claude but we can follow the pattern and conclude that Claude4 will be in line with the others.
Then we have ChatGPT 5.0. This is the subject of much speculation, a lot of it dropped by OpenAI.
At this point, nobody really knows what it is although we did get a bit of insight here and there. Some are speculating the delay in release is because the company actually is at AGI level. While this is no substantiated, we can also conclude that OpenAI is working on something that will compare with the others.
Massive Step Forward
What we are proposing is not uncommon in the technology world. The third generation of something is usually where things take off.
With the chatbots, we have different numbers. However, when we look at the major releases, we can see how, since going public, we are on our third iteration.
ChatGPT 3 was followed by 4 and then will have 5. There were, of course, iterations in between but they aren't exactly new models. There were upgrades simply to Grok release 1.5 after 1.0. That wasn't a completely new model.
The main question around these next ones will be cognitive and reasoning capabilities. Some argue that isn't going to happen and it might not. Nevertheless, we are going to see another expansion in the token window, a more refined understanding of the world, and a better ability to predict the next token.
All of this favors an exponential step forward.
We will have to see what the rest of the year holds. My guess is that we have a new generation by all these players in the next 6 months (at the most).
Each new release will send the LLM followers nuts, proclaiming a new leader. Each time, however, we will simply be scaling higher up the curve.
Posted Using InLeo Alpha