It has been 91 days since the launch of Hive Punks.

I have had a lot of time to think of what went wrong, what went right, and what I would do differently. While I expected to have a good turn out since most people know me here on Hive and the announcement just prior to Hivefest, I did not expect it to sell out in 36 hours.

This was of course the best possible outcome, but it did create a unique situation where I had to baby sit the launch while hanging out at Hivefest and some third party technical issues cropped up that caused a lot of delays.
Now that around 3 months have passed, I have had time to think about things and work on some improvements for Hive Punks.
When I originally came up with the idea of Hive Punks, I planned on knocking it out in 1-2 days. It was a proof of concept to show that Hive can do large scale NFT projects and to break the mold. Within the first day of developing I came up with more and more ideas to provide a better experience.
Some of these were great ideas, and some I regret. One of the ones that took a large portion of my time was what I called Real-Time Rarity, something I have never seen attempted. With this, every Punk's rarity updated in real time as new Punks were minted. This was really cool from a user standpoint as well as technology point of view. It didn't come without side effects.
While Real-Time Rarity worked really well in my tests with well over 10,000 NFTs being speed minted, at launch it possed problems. The third party system I used to handle this started to choke causing the metadata process to fall behind.
During the launch there were two processes running in parallel, the first was the minting. This process monitored the Hive blockchain for Hive transfers to @punksonhive. It would validate the transfer and then mint the NFTs on Hive Engine.
Due to the fact I had no guarantee what the next NFT ID was, I created a second process to run after the minting process. This process would monitor the Hive Engine blockchain for new PUNK nfts and collect the metadata via IPFS. Doing things this way assured I knew the correct NFT IDs to insert into my database. This database maintained all the NFT ids and their metadata to calculate rarity and provide fast access to NFT details. Without this, everything would depend on IPFS which would have caused a lot of performance problems.
The main reason to have a second process was because the minting process did not return an NFT ID that was minted. In fact, it didn't even guarantee anything got minted. This is due to the fact everything on Hive Engine is a custom JSON that then gets validated and then processed if the criteria is met. This second process was necessary to know without a shadow of a doubt, what the NFT ID is. I could have just used the next ID in line, but this created a risk of data becoming de-syncronized, the risk was microscopic, but it was there.
I don't think I would have done this differently going forward, it worked really well. The Real-Time Rarity though required a lot of clever design and programming and ultimately didn't matter since all Punks were sold out and ultimately stammped with their final rarity within 36 hours.
In addition to Rare-Time Rarity, another unique thing I did was guarantee every single NFT was provably fair and no one got an unfair advantage. I couldn't even tell what was going to happen until a Punk was minted on the blockchain. While my primary reason for doing this was to provide trust, I also wanted to prove a point that it could be done where almost all NFT projects don't have this level of trust and validation.
Data integrity was critical to me, I wanted to make sure every NFT minted properly and all metadata was accounted for properly. I am extremely happy with the results, while there were a few problems most came out perfect. These "problems" actually turn into collectables as people love to have unique defects.
There are a couple unique "glitches" that happened due to oversights on my part.

One of them for example is Punk #1773. You can see here the "spots" blemish leaked through the hat. This is due to the order the layers were stacked to create the final image. I did a lot of testing to come up with the best way to layer images to prevent overlaps. I messed up with blemishes, and in some combinations you get artifacts like this.
There is one NFT that the image didn't generate, and it is just a white square. I'm not going to tell you which one, but there is one. The IPFS data property for the NFTs is set to write once (I chose this) and these "defects" can't be "corrected". To some, this makes them more valuable.
As I said, this project was originally 1-2 days, to build a clone of Crypto Punks for Hive since we were one of the few blockchains that have not done it yet. After I started, I really wanted to build more and make it better than the original idea. The scope of the project grew quickly so I had to focus on what was most critical for launch so I can have it done by Hivefest.
One thing that proved to be very difficult is image hosting. Hive Punks are 2.5KB images, very tiny images compared to most and shouldn't pose any problem, even with 10,000 of them. The backend I used (Supabase) had a lot of problems though and during launch I was getting constant data outages that I could never get an answer to. I ended up having to make some real-time shifts to move image hosting multiple times to come up with a stable solution. Because these images were initially fetched from IPFS, this was a slow process. I did a few work arounds to resolve this and the problem went away. Shortly later I made some tweaks to eliminate image hosting costs.
Believe it or not, Hive Punks was created with zero costs. This was important to me, not to be cheap but to prevent a lifetime dependency of reoccuring fees. While I wanted to prevent any reoccuring costs, performance degration was not acceptable. Many things were done to assure fantastic performance and reliability, all without introducing reoccuring fees.
One of the problems I ran into is a Hive Engine testnet. There is was only one publicly available testnet for Hive Engine. This was critical for me as I had no clue what I was doing and I had to learn during this short 2-3 period as well as knock out a working system. After making a lot of progress the testnet was taken down and I was left in the dark. I had to scramble and find a solution so I can continue to make progress and test. I managed to figure out how to get my own testnet up and running and remove my dependency on third party nodes. This was difficult, but was a great learning experience.
During launch my biggest problem was my dependency on Supabase. This repeatedly slowed down the 2nd process that monitored for new NFTs and copied over the metadata. Many attempts to find and solve the solution was unsuccessful and I spent most of my time just waiting for it to come back online. It was shuttin down for 5-10 minutes at a time. Moving image hosting from Supabase helped a lot and reduced how often it would crash, but it was still happening. The amount of concurrent users using the app, viewing their Punks, and minting new ones was too much to bear.
This was a problem unique to me, because I was truly minting Punks on demand and not just handing out the next pre-generated NFT like 99%+ of the NFT projects do. If I pregenerated all 10,000 Punks with metadata and just handed out a random ID, the process would have been instant, but highly corruptible.
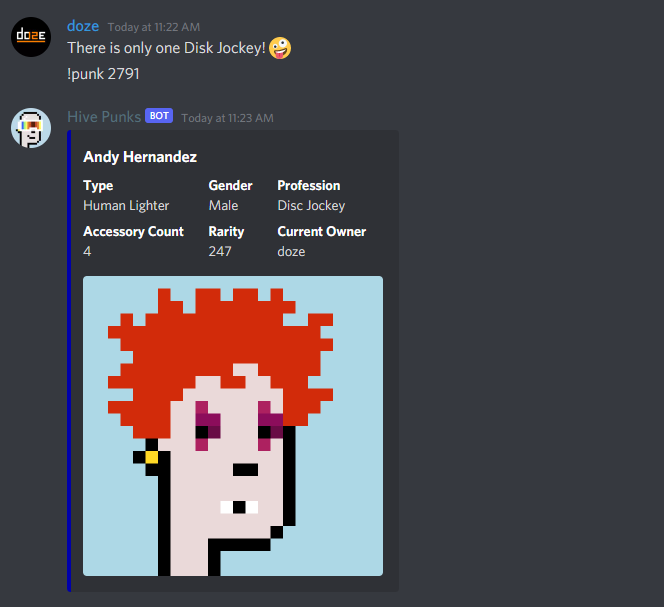
During launch I started to work on a Discord bot that allows people to get details of Hive Punks right from Discord. I think this was a critical step I should have done prior to launch. Never underestimate social aspects. These are what keep people interested and bring the most entertainment. Juggling doing this while having all the technical issues was as challenge.
I could go on for another hour, but I wanted to share some thoughts of the process and experiences behind Hive Punks.
I have a lot of ideas for Hive Punks and many more projects I am working on.
Be sure to hop on our Discord if you want to get involved.

Posted Using LeoFinance Beta