"AI" benchmarks can be gamed with some effort. I have seen scenarios where a changing of the order of the answers in an MCQ resulting in drastically difference performance "AI". When there is a massive gap in benchmarks between models, we can also see that they are either an older model or of a different size. In such cases, the users don't even need the benchmark to figure out which is better.
LM Arena Offer Blind Testing
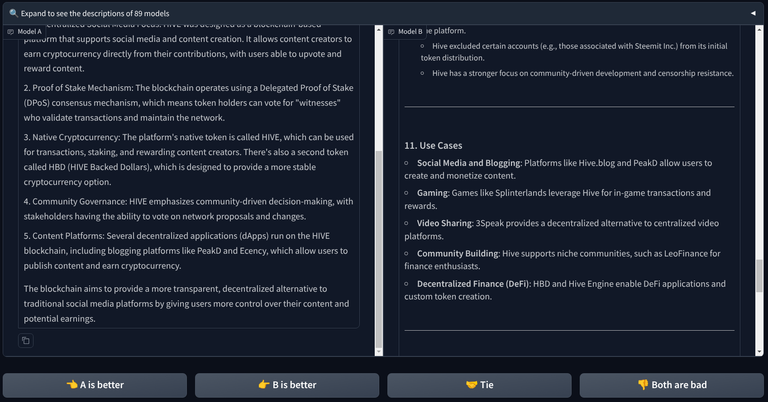
I asked a very short and simple prompt about HIVE and I got the results in very fast. The paid subscriptions are handled by LM Arena. Uses can select one of four options. Once the the voting is complete, the model names are revealed.

The results of these votes are used to rank various models against each other. The votes come from a small sample of enthusiasts who already know about LM Arena. Since the same userbase is the one that is most likely to know and understand "AI", I don't think the sample size is going to bea problem.
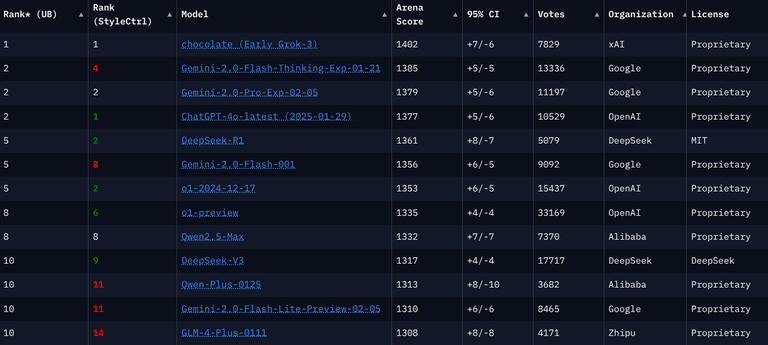
Current Leaderboard With xAI on Top