HiveStats: Developer's Insight

Introduction
As I do reply to some of the posts about HiveStats, you might already know that I'm the developer who is working on it, on behalf of LeoFinance. It might feel like I'm trying to steal their credit and trying to shout out to the whole universe about it; I do also feel a little like so, not going to lie. But, frankly, I'm rather a bit excited about it, that's all the reason. I was eager to do a project on Hive and working on HiveStats allowed me that even though it isn't my project. I'm excited because lots of people use it, and give feedback about it. I try to engage, fix bugs as quickly as possible to keep the illusion as if it is imperfect. So, in summary, this is the way I'm fighting my anxiety back.
I do love talking about programming concepts, I sometimes talk all day long. I did write up two posts about it last year, in the hopes of getting some engagement. While they got some votes from curation accounts, I got no reply, which discouraged me from writing any further posts. It could be because maybe my content wasn't up to the standards, or it was too abstract. Fast forward to 2022 and I now have the experience of developing an already existing app from scratch, which is less abstract and more practical, and popular, of course. So, allow me to share my shortcomings, struggles and solutions to those, so to call my experience, while developing HiveStats. I do apologize to all of you for my brashness for using this HiveStats popularity as an opportunity.
Lack of Documentation
(searching what rshare means and its denominator)
I struggled with documentation the most, this was the most time-consuming issue by far. Documentation on Hive API methods was ok, but I can't say the same for the formulas and terms. To overcome it, I scraped example applications in the documentation, checked open-source projects that I know of, read lots of old discord messages. My Hive Engine experience was also similar.
I do plan to develop a handbook kind of website with search functionality due to this, to help other people like me.
Account History
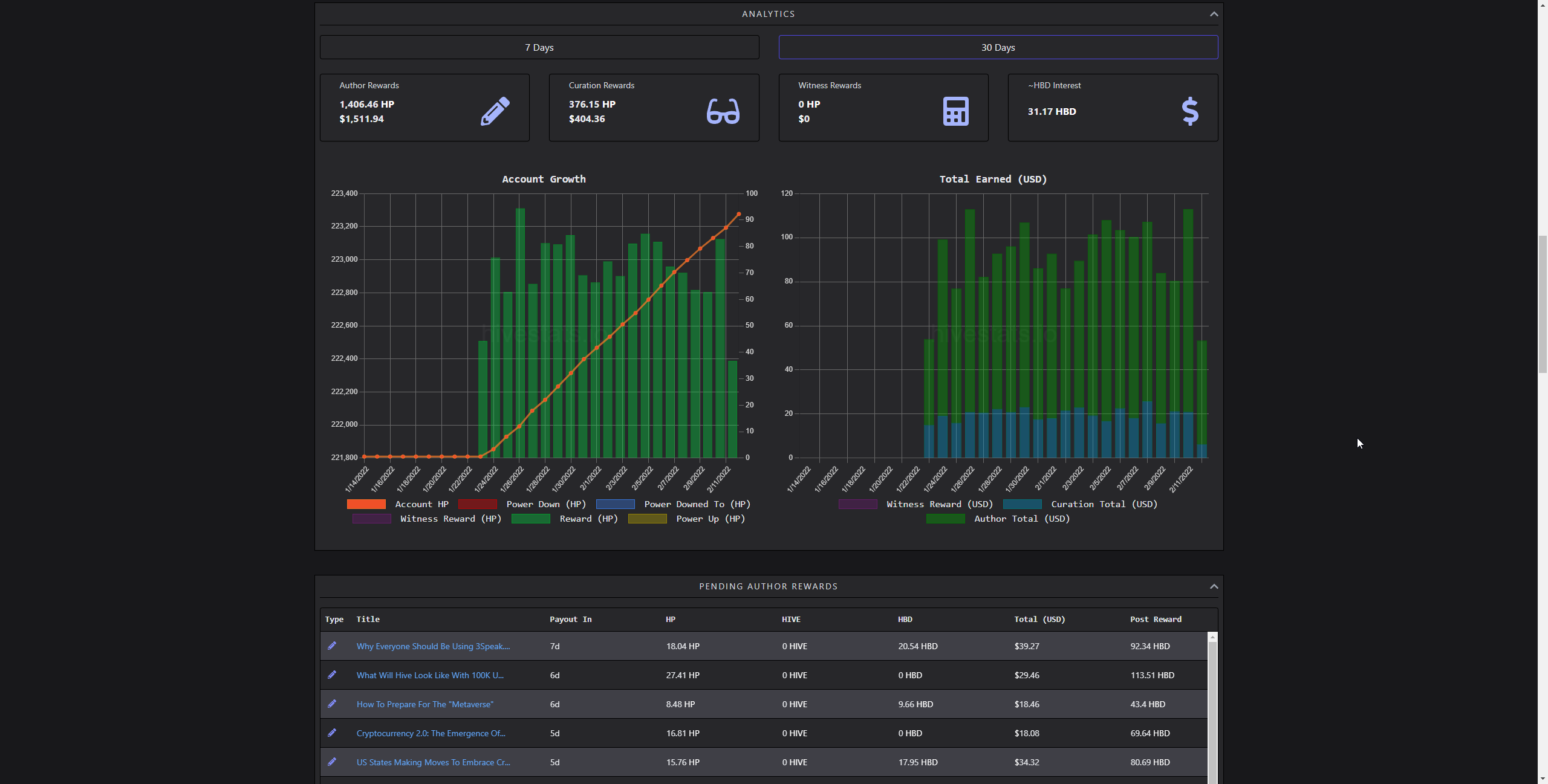
(showing partly loaded analytics)
Most of the stuff is calculated through parsing accounts' operations over time. For inactive account's like mine, it is just a simple call; but for people like @taskmaster4450, it gets dirty pretty quick. The thing is, reading the history is limited to 1000 items per request. There isn't a way of reading a week of history or month, so results of requests are read to figure out if it's past a month or not. Using that way, getting 50 history requests becomes sync as each request depends on another.
It was an issue of the old iteration of HiveStats, which I did solve in the V3 update. I did also improve upon it in the current iteration. The trick is making them partly async. Without boring details, I do predict how many requests it would take by using the first several requests. Later, I fetch them in batches. If they overshoot, I filter, if not, batch again. That way, it becomes several sync requests of async rather than all sync.
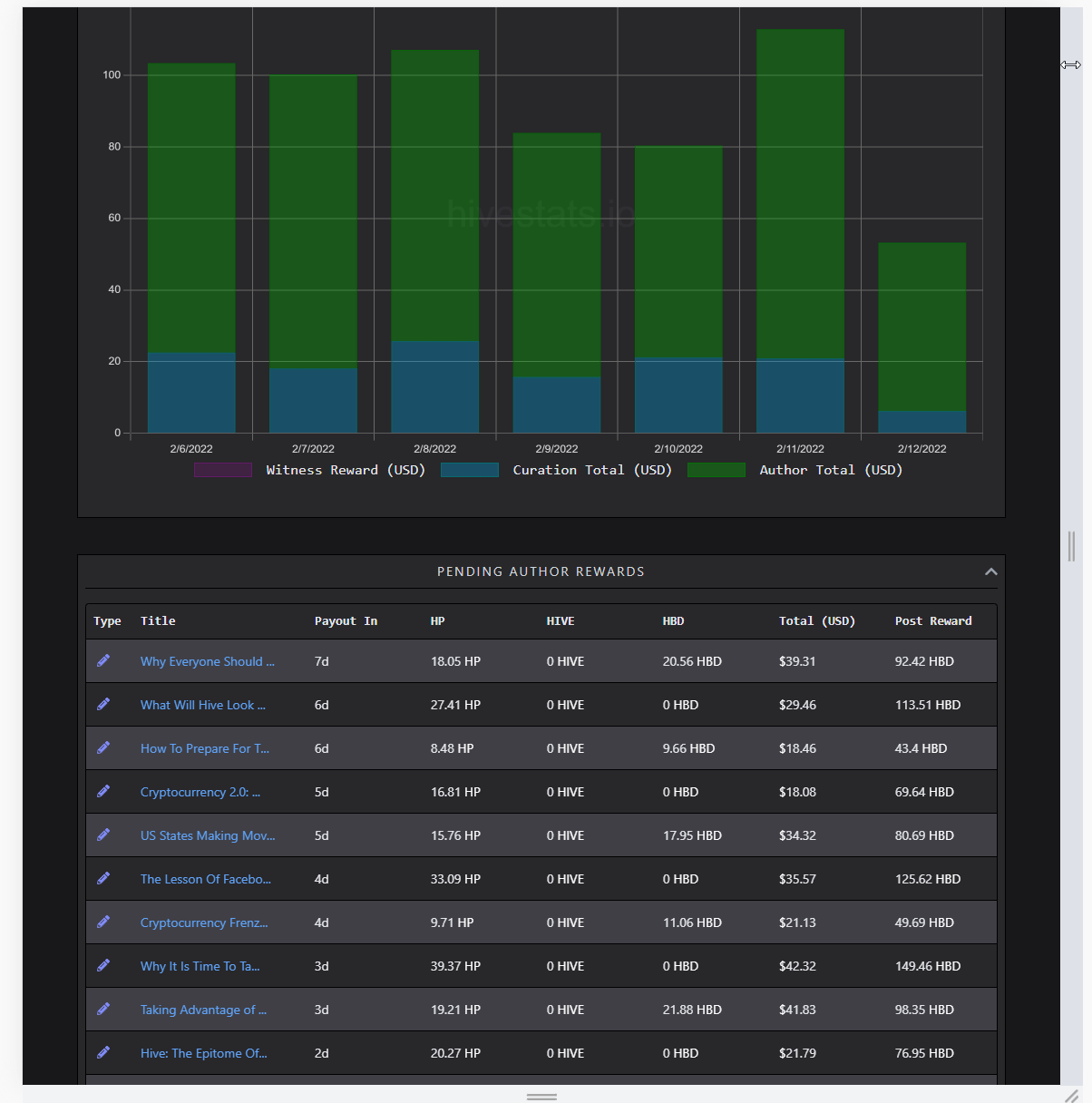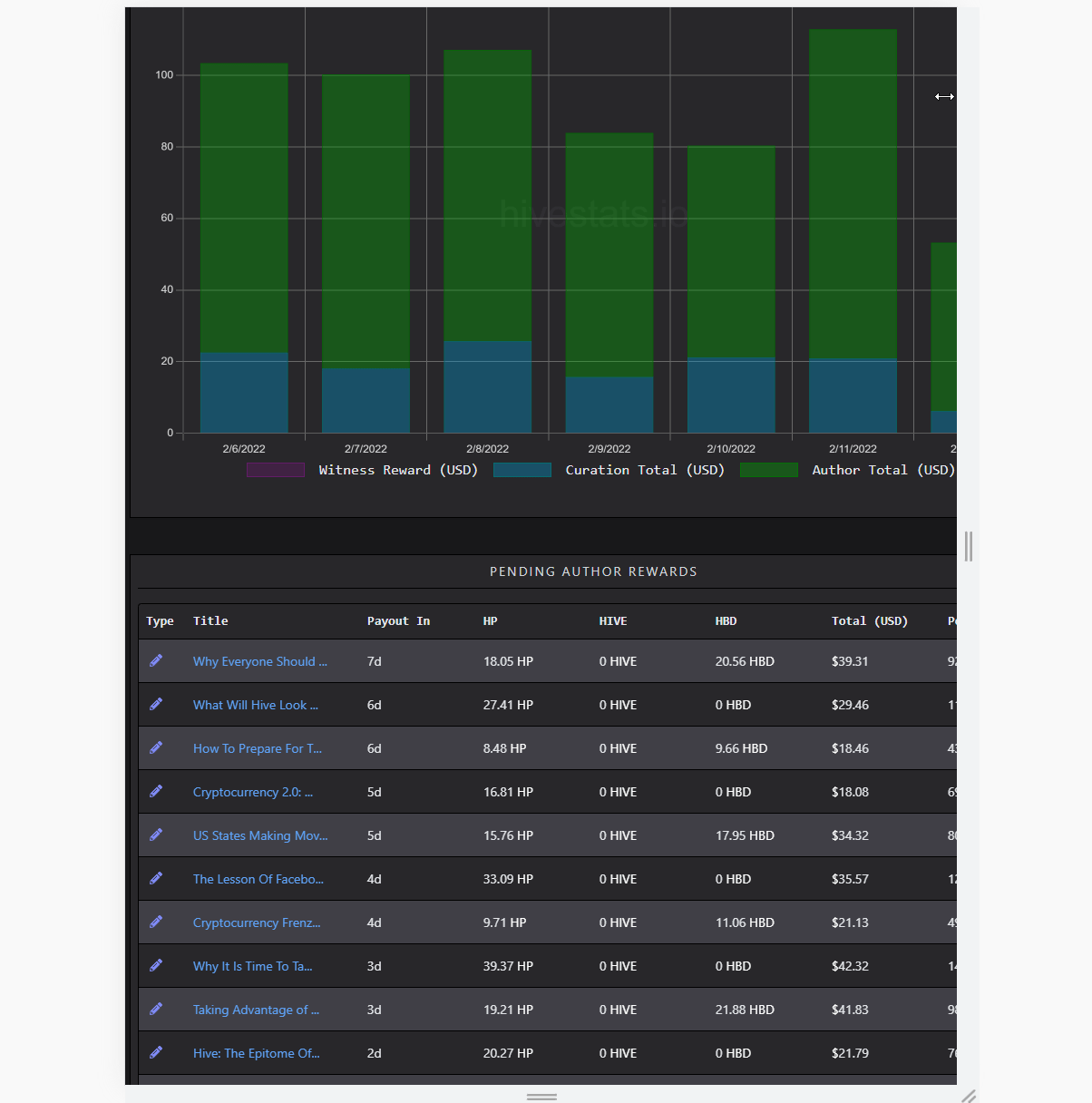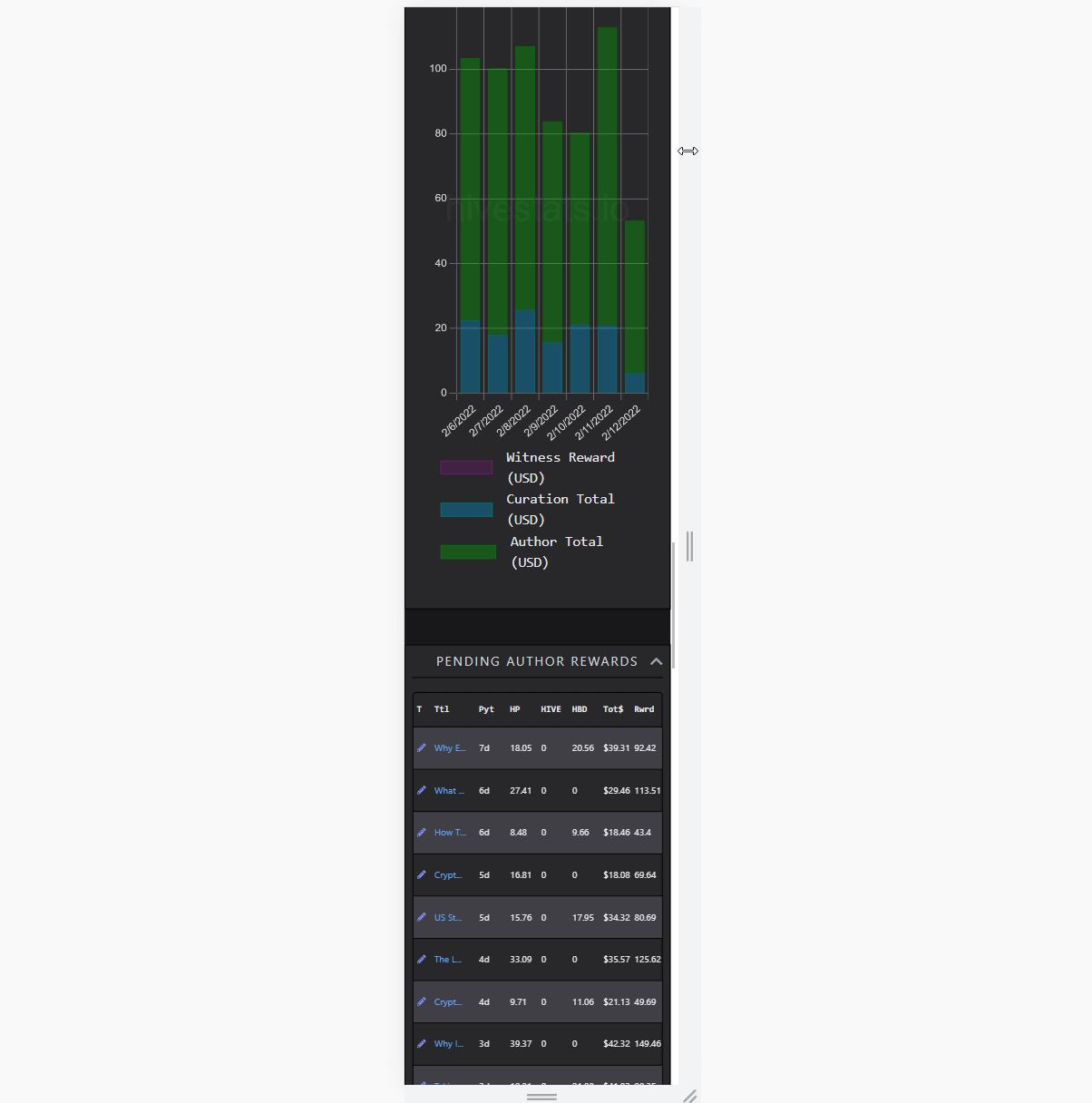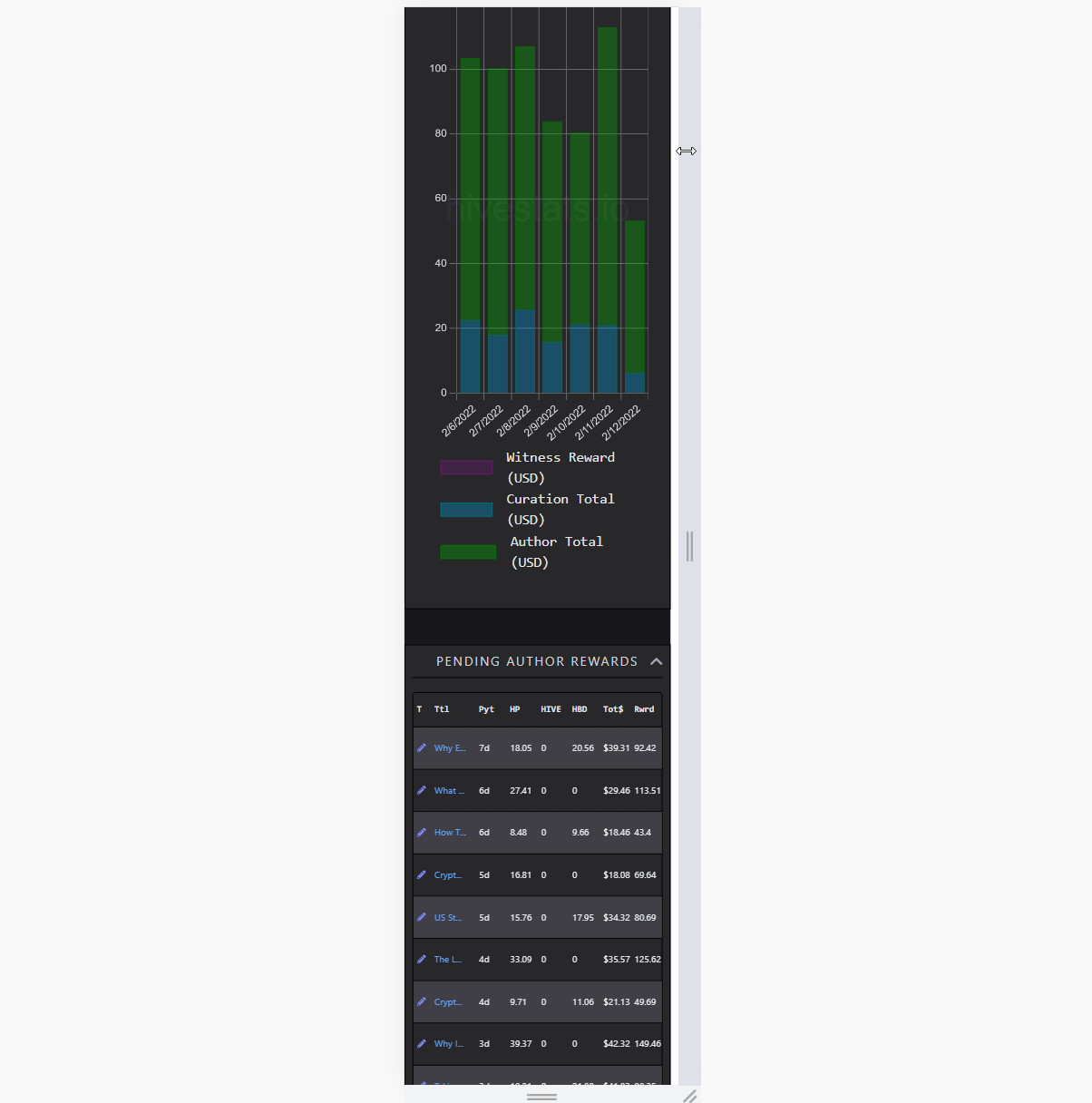
Curation Rewards and Operations
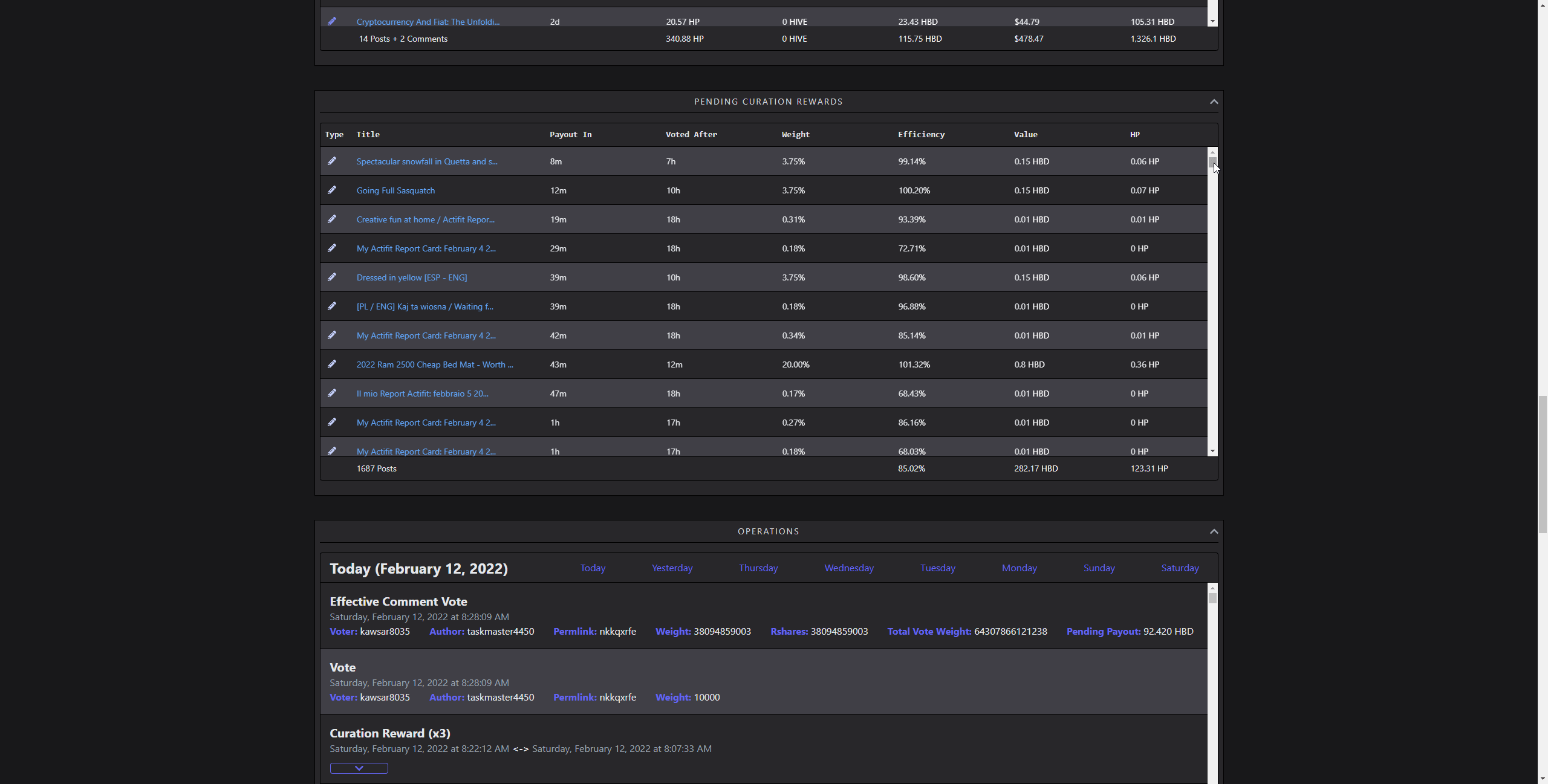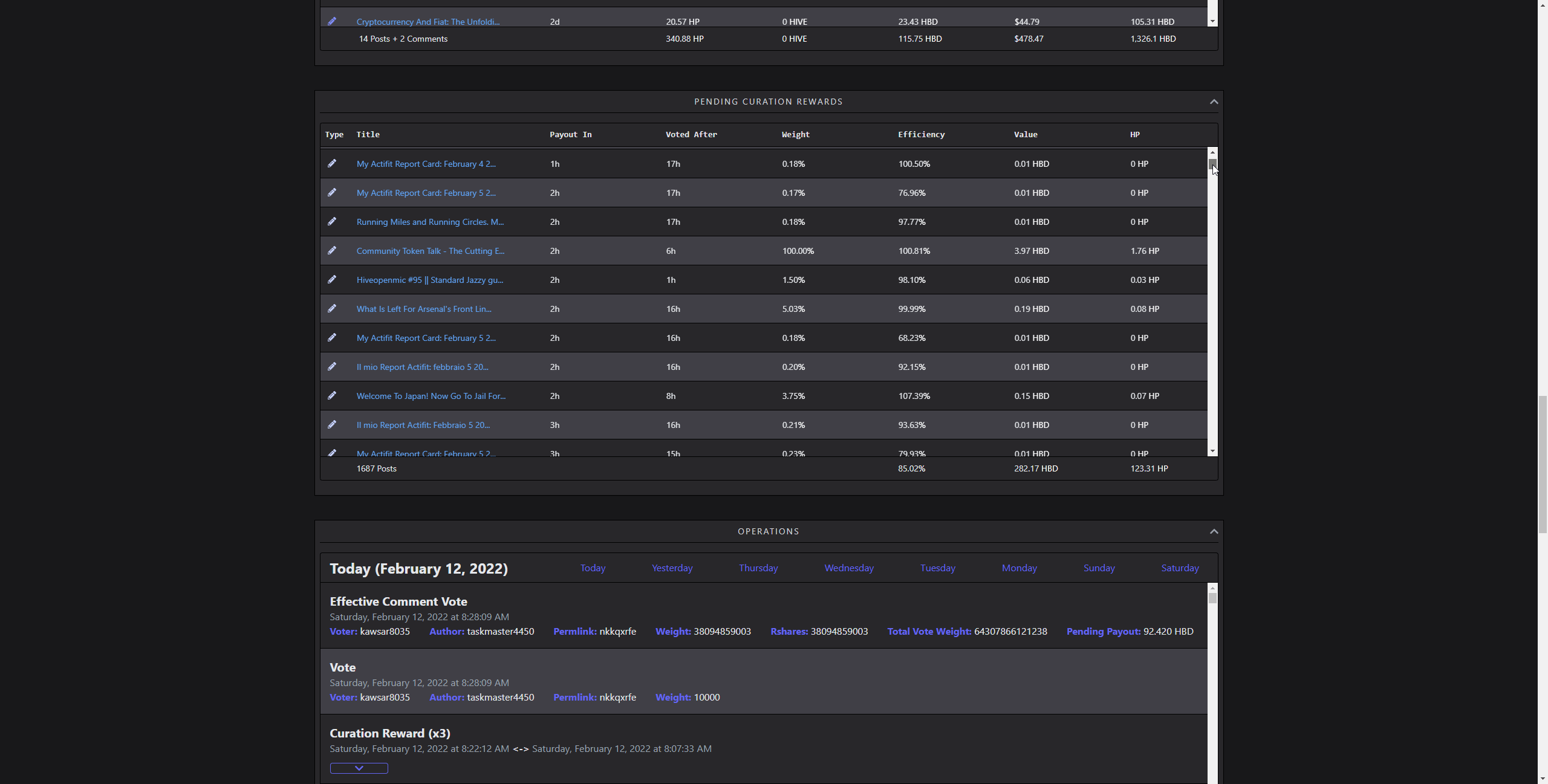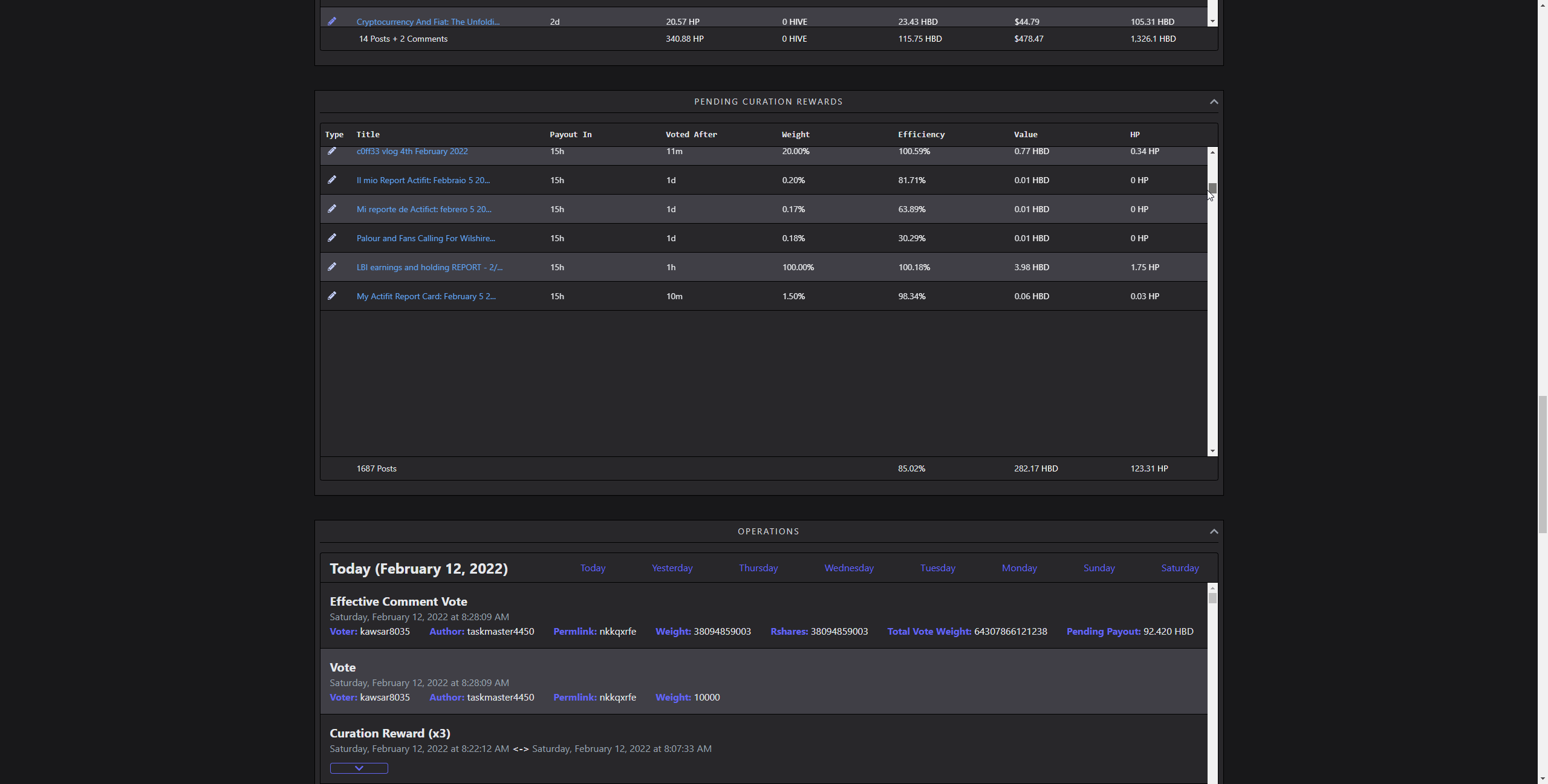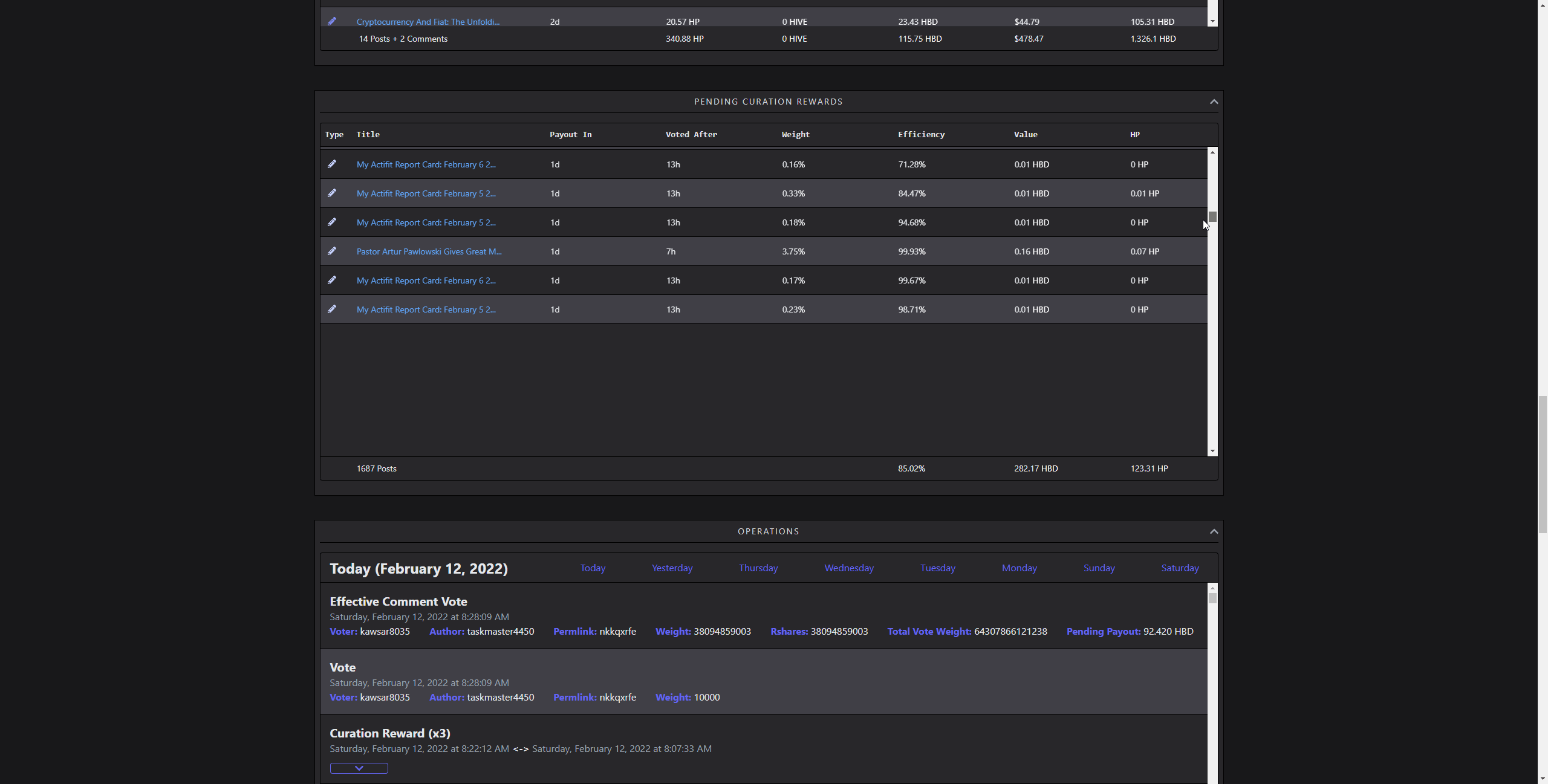
(scrolling through 1657 rows)
Visualizing lots of data without combining them into something, like a chart is demanding. Rendering several thousands of complex elements as rows of a table takes time. Updating it on the go several hundred times makes the framerate unstable. It doesn't matter how fast it is fetched or parsed, if it feels sluggish, that's a bad UX. I did solve this by using a technique called windowing. So, rendering only the parts user is currently seeing, and reusing old elements in the process. While doing that, simulating scroll behaviour and memoizing heavy renders is also crucial. That way, it creates an illusion of lots of items, in reality, showing only a dozen of them.
Mobile Support
(simulating narrower screen view)
Mobile support is hard, making tables mobile friendly is harder. I struggle a lot to fit every bit of information on the tables, without horizontal scrolling. I did reduce the font size, used abbreviations, cut most of the title on lower screens to fit everything. While the execution was easy, it took lots of time to test and figure perfect values.
Making it Feel Reactive

(fetching post data while updating the table)
As I said in a previous paragraph, if a UI feels sluggish, that's a bad UX. In the frontend world, the most important thing is controlling how a user feels. Websites with more features might get lower traffic due to how they act to the user's actions and vice-versa. For HiveStats, unlike other sites, loading an account is the most important action of the user, so making it reactive was necessary. The difference between V3 and V4 is not much in terms of raw speed, but as the latter feels more reactive and updates constantly, it makes the user focus on updated data rather than waiting for it. That way, it cheats badly, creates the illusion of being far faster. That's the power of UX. React's one-way data flow and using memoization was crucial in this process.
Important Techs/Libraries I Used
- TypeScript
- React
- TailwindCSS
- React Router
- React Virtuoso
- DHive
- Formik + Yup
- Immer
- date-fns
- nginx
- Docker
So, hope you like it. I tried to not be boring while providing enough data and making it a quick read. If you have any questions, I am happy to reply to all of them. See you later, thanks for tuning in!
Posted Using LeoFinance Beta
